 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Techniques for Training Consistency Models
Paper and Code
Oct 22, 2023


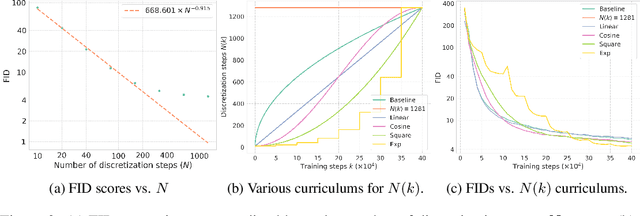
Consistency models are a nascent family of generative models that can sample high quality data in one step without the need for adversarial training. Current consistency models achieve optimal sample quality by distilling from pre-trained diffusion models and employing learned metrics such as LPIPS. However, distillation limits the quality of consistency models to that of the pre-trained diffusion model, and LPIPS causes undesirable bias in evaluation. To tackle these challenges, we present improved techniques for consistency training, where consistency models learn directly from data without distillation. We delve into the theory behind consistency training and identify a previously overlooked flaw, which we address by eliminating Exponential Moving Average from the teacher consistency model. To replace learned metrics like LPIPS, we adopt Pseudo-Huber losses from robust statistics. Additionally, we introduce a lognormal noise schedule for the consistency training objective, and propose to double total discretization steps every set number of training iterations. Combined with better hyperparameter tuning, these modifications enable consistency models to achieve FID scores of 2.51 and 3.25 on CIFAR-10 and ImageNet $64\times 64$ respectively in a single sampling step. These scores mark a 3.5$\times$ and 4$\times$ improvement compared to prior consistency training approaches. Through two-step sampling, we further reduce FID scores to 2.24 and 2.77 on these two datasets, surpassing those obtained via distillation in both one-step and two-step settings, while narrowing the gap between consistency models and other state-of-the-art generative models.