Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Captioning
Paper and Code
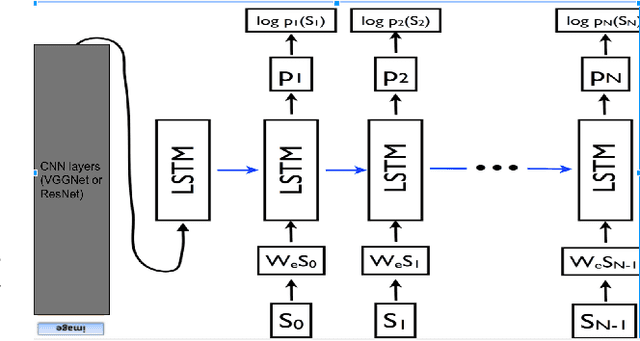
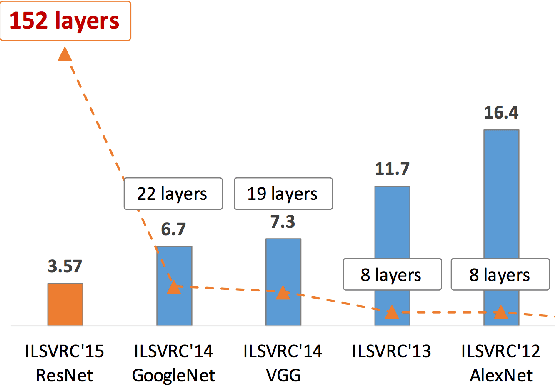
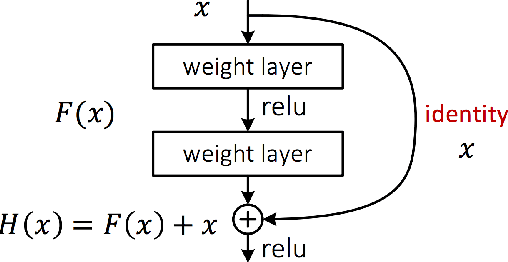
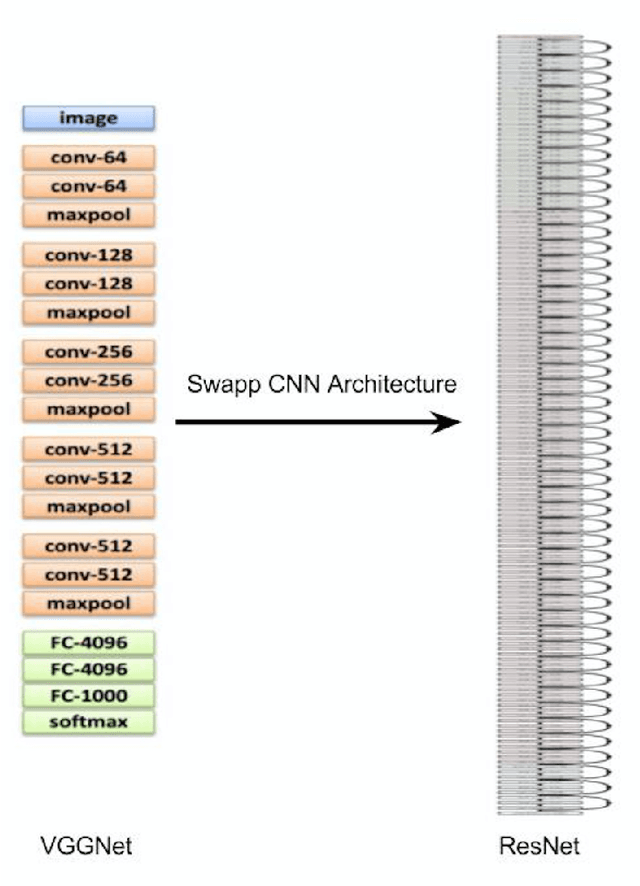
This paper discusses and demonstrates the outcomes from our experimentation on Image Captioning. Image captioning is a much more involved task than image recognition or classification, because of the additional challenge of recognizing the interdependence between the objects/concepts in the image and the creation of a succinct sentential narration. Experiments on several labeled datasets show the accuracy of the model and the fluency of the language it learns solely from image descriptions. As a toy application, we apply image captioning to create video captions, and we advance a few hypotheses on the challenges we encountered.
* arXiv admin note: text overlap with arXiv:1609.06647 by other authors
View paper on