 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Activity Recognition Using Cascaded Dual Attention CNN and Bi-Directional GRU Framework
Paper and Code
Aug 09, 2022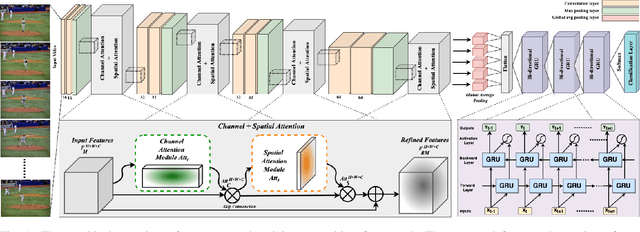
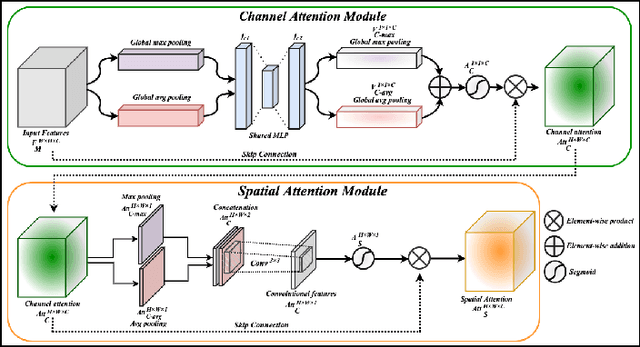

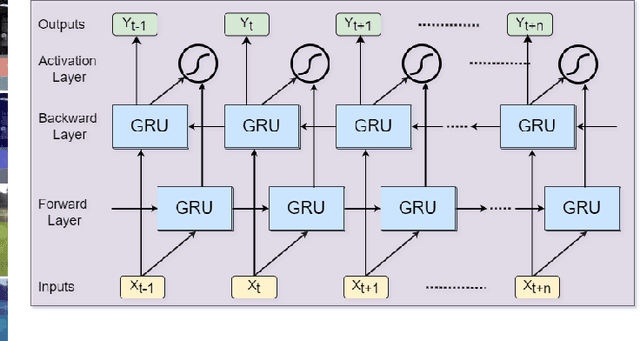
Vision-based human activity recognition has emerged as one of the essential research areas in video analytics domain. Over the last decade, numerous advanced deep learning algorithms have been introduced to recognize complex human actions from video streams. These deep learning algorithms have shown impressive performance for the human activity recognition task. However, these newly introduced methods either exclusively focus on model performance or the effectiveness of these models in terms of computational efficiency and robustness, resulting in a biased tradeoff in their proposals to deal with challenging human activity recognition problem. To overcome the limitations of contemporary deep learning models for human activity recognition, this paper presents a computationally efficient yet generic spatial-temporal cascaded framework that exploits the deep discriminative spatial and temporal features for human activity recognition. For efficient representation of human actions, we have proposed an efficient dual attentional convolutional neural network (CNN) architecture that leverages a unified channel-spatial attention mechanism to extract human-centric salient features in video frames. The dual channel-spatial attention layers together with the convolutional layers learn to be more attentive in the spatial receptive fields having objects over the number of feature maps. The extracted discriminative salient features are then forwarded to stacked bi-directional gated recurrent unit (Bi-GRU) for long-term temporal modeling and recognition of human actions using both forward and backward pass gradient learning. Extensive experiments are conducted, where the obtained results show that the proposed framework attains an improvement in execution time up to 167 times in terms of frames per second as compared to most of the contemporary action recognition methods.