 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Reading Does Reading Comprehension Require? A Critical Investigation of Popular Benchmarks
Paper and Code
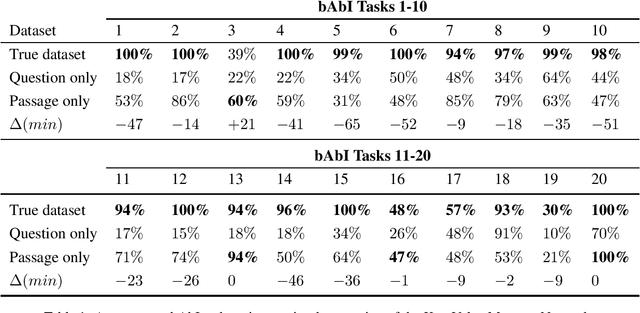
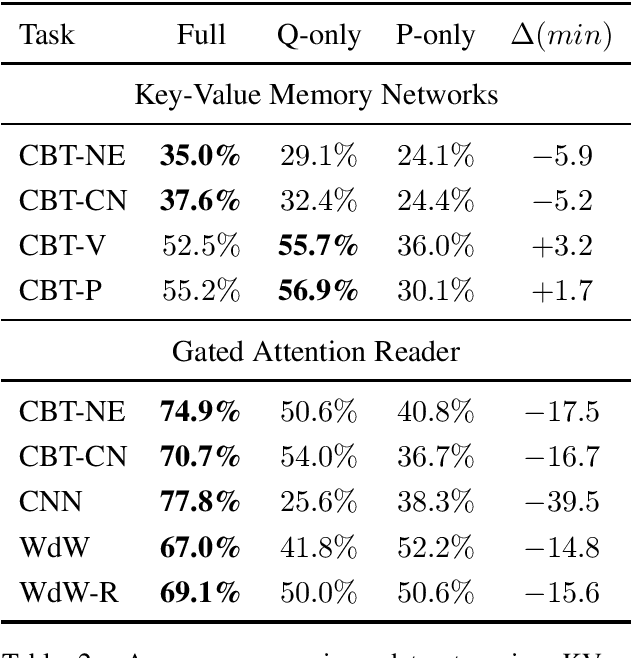


Many recent papers address reading comprehension, where examples consist of (question, passage, answer) tuples. Presumably, a model must combine information from both questions and passages to predict corresponding answers. However, despite intense interest in the topic, with hundreds of published papers vying for leaderboard dominance, basic questions about the difficulty of many popular benchmarks remain unanswered. In this paper, we establish sensible baselines for the bAbI, SQuAD, CBT, CNN, and Who-did-What datasets, finding that question- and passage-only models often perform surprisingly well. On $14$ out of $20$ bAbI tasks, passage-only models achieve greater than $50\%$ accuracy, sometimes matching the full model. Interestingly, while CBT provides $20$-sentence stories only the last is needed for comparably accurate prediction. By comparison, SQuAD and CNN appear better-constructed.