 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHookNet: multi-resolution convolutional neural networks for semantic segmentation in histopathology whole-slide images
Paper and Code
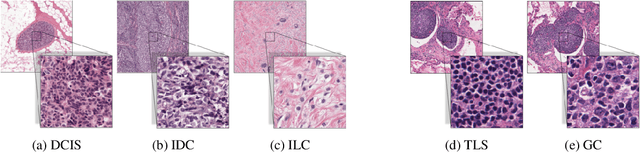
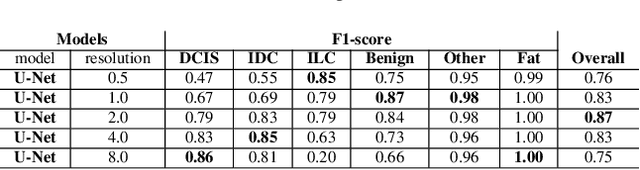
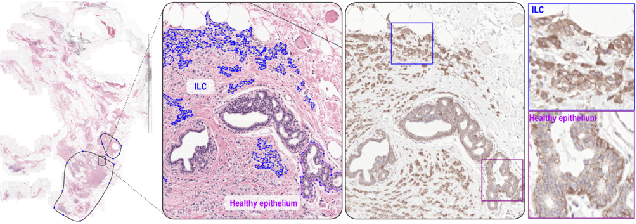
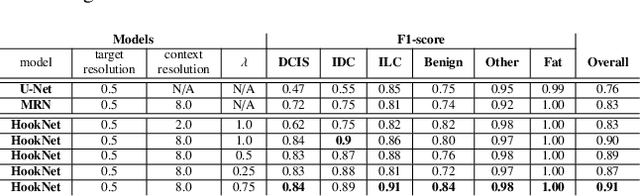
We propose HookNet, a semantic segmentation model for histopathology whole-slide images, which combines context and details via multiple branches of encoder-decoder convolutional neural networks. Concentricpatches at multiple resolutions with different fields of view are used to feed different branches of HookNet, and intermediate representations are combined via a hooking mechanism. We describe a framework to design and train HookNet for achieving high-resolution semantic segmentation and introduce constraints to guarantee pixel-wise alignment in feature maps during hooking. We show the advantages of using HookNet in two histopathology image segmentation tasks where tissue type prediction accuracy strongly depends on contextual information, namely (1) multi-class tissue segmentation in breast cancer and, (2) segmentation of tertiary lymphoid structures and germinal centers in lung cancer. Weshow the superiority of HookNet when compared with single-resolution U-Net models working at different resolutions as well as with a recently published multi-resolution model for histopathology image segmentation