 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHippo: Taming Hyper-parameter Optimization of Deep Learning with Stage Trees
Paper and Code
Jun 22, 2020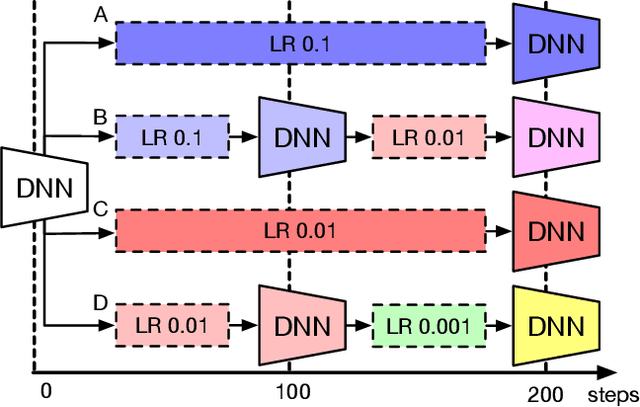

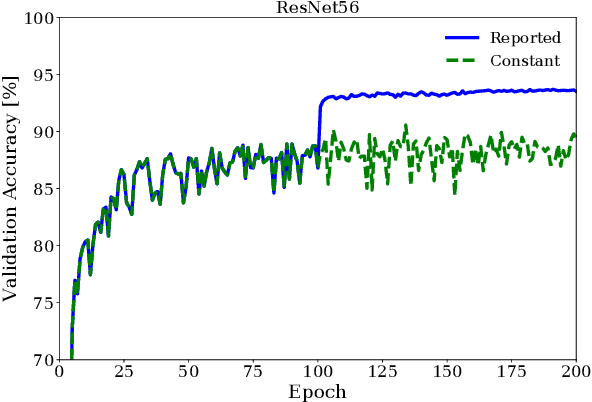
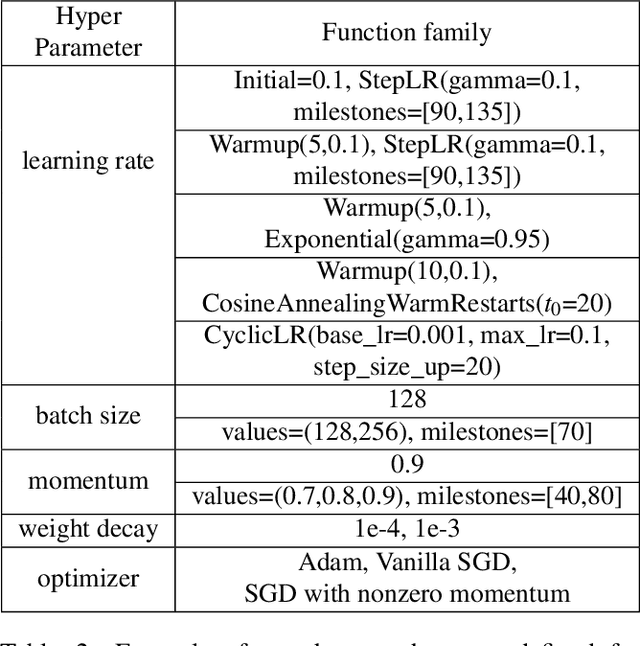
Hyper-parameter optimization is crucial for pushing the accuracy of a deep learning model to its limits. A hyper-parameter optimization job, referred to as a study, involves numerous trials of training a model using different training knobs, and therefore is very computation-heavy, typically taking hours and days to finish. We observe that trials issued from hyper-parameter optimization algorithms often share common hyper-parameter sequence prefixes. Based on this observation, we propose Hippo, a hyper-parameter optimization system that removes redundancy in the training process to reduce the overall amount of computation significantly. Instead of executing each trial independently as in existing hyper-parameter optimization systems, Hippo breaks down the hyper-parameter sequences into stages and merges common stages to form a tree of stages (called a stage-tree), then executes a stage once per tree on a distributed GPU server environment. Hippo is applicable to not only single studies, but multi-study scenarios as well, where multiple studies of the same model and search space can be formulated as trees of stages. Evaluations show that Hippo's stage-based execution strategy outperforms trial-based methods such as Ray Tune for several models and hyper-parameter optimization algorithms, reducing GPU-hours and end-to-end training time significantly.