 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHinFlair: pre-trained contextual string embeddings for pos tagging and text classification in the Hindi language
Paper and Code

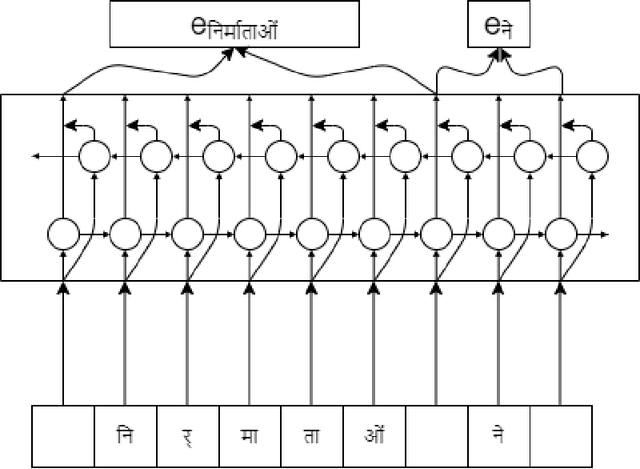


Recent advancements in language models based on recurrent neural networks and transformers architecture have achieved state-of-the-art results on a wide range of natural language processing tasks such as pos tagging, named entity recognition, and text classification. However, most of these language models are pre-trained in high resource languages like English, German, Spanish. Multi-lingual language models include Indian languages like Hindi, Telugu, Bengali in their training corpus, but they often fail to represent the linguistic features of these languages as they are not the primary language of the study. We introduce HinFlair, which is a language representation model (contextual string embeddings) pre-trained on a large monolingual Hindi corpus. Experiments were conducted on 6 text classification datasets and a Hindi dependency treebank to analyze the performance of these contextualized string embeddings for the Hindi language. Results show that HinFlair outperforms previous state-of-the-art publicly available pre-trained embeddings for downstream tasks like text classification and pos tagging. Also, HinFlair when combined with FastText embeddings outperforms many transformers-based language models trained particularly for the Hindi language.