Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh performance ultra-low-precision convolutions on mobile devices
Paper and Code
Dec 06, 2017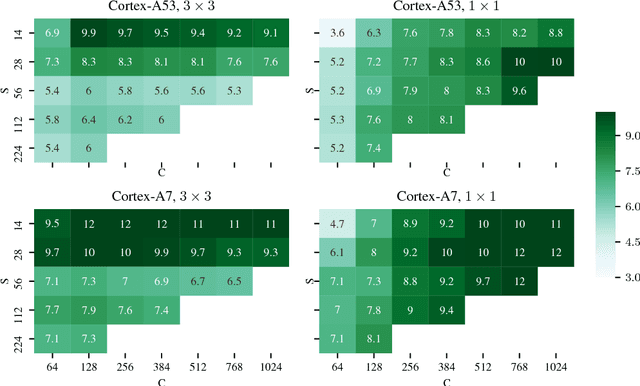
Many applications of mobile deep learning, especially real-time computer vision workloads, are constrained by computation power. This is particularly true for workloads running on older consumer phones, where a typical device might be powered by a single- or dual-core ARMv7 CPU. We provide an open-source implementation and a comprehensive analysis of (to our knowledge) the state of the art ultra-low-precision (<4 bit precision) implementation of the core primitives required for modern deep learning workloads on ARMv7 devices, and demonstrate speedups of 4x-20x over our additional state-of-the-art float32 and int8 baselines.
* Presented at NIPS 2017, Machine Learning on the Phone and other
Consumer Devices workshop
View paper on