 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Multi-Scale Attention for Semantic Segmentation
Paper and Code
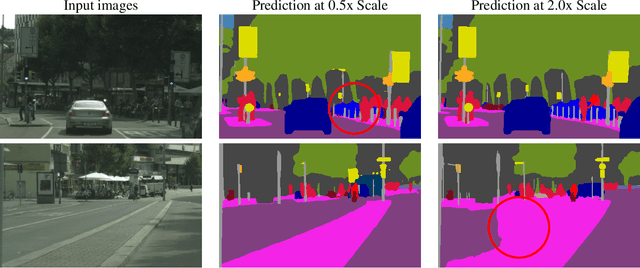

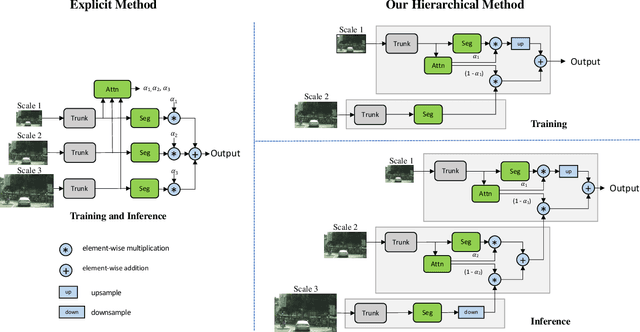

Multi-scale inference is commonly used to improve the results of semantic segmentation. Multiple images scales are passed through a network and then the results are combined with averaging or max pooling. In this work, we present an attention-based approach to combining multi-scale predictions. We show that predictions at certain scales are better at resolving particular failures modes, and that the network learns to favor those scales for such cases in order to generate better predictions. Our attention mechanism is hierarchical, which enables it to be roughly 4x more memory efficient to train than other recent approaches. In addition to enabling faster training, this allows us to train with larger crop sizes which leads to greater model accuracy. We demonstrate the result of our method on two datasets: Cityscapes and Mapillary Vistas. For Cityscapes, which has a large number of weakly labelled images, we also leverage auto-labelling to improve generalization. Using our approach we achieve a new state-of-the-art results in both Mapillary (61.1 IOU val) and Cityscapes (85.1 IOU test).