 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeuristical choice of SVM parameters
Paper and Code
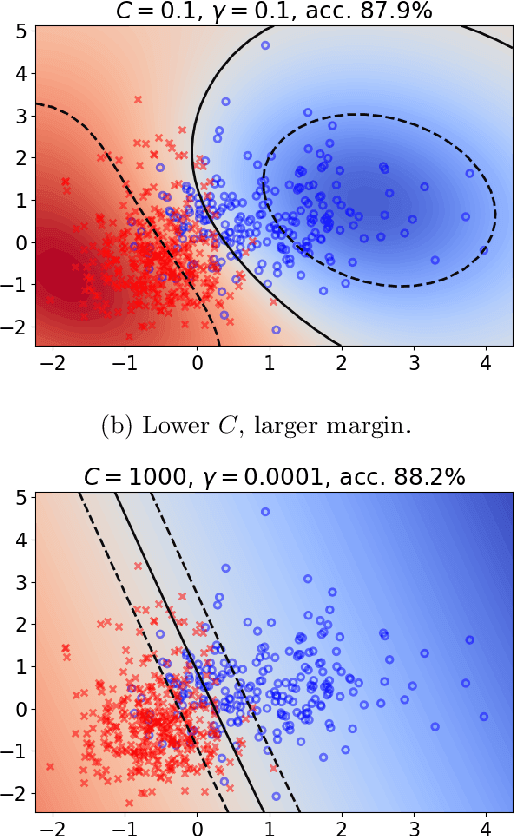
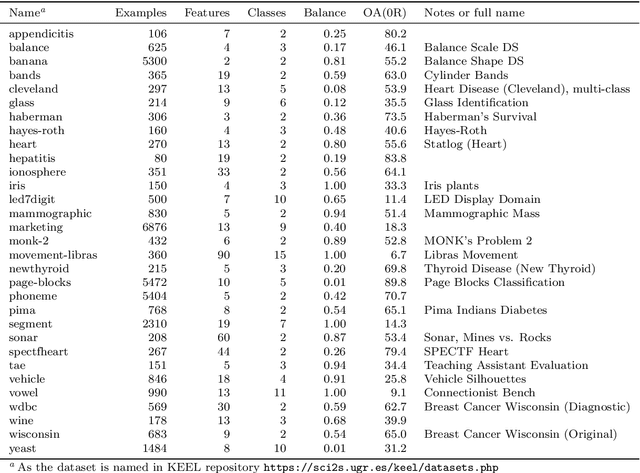
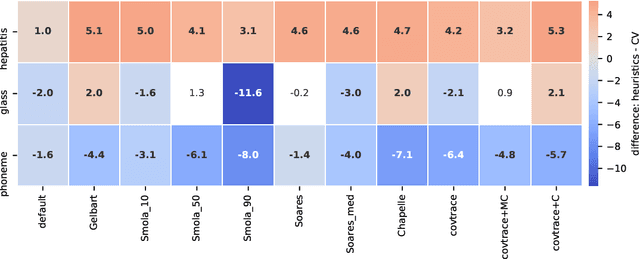
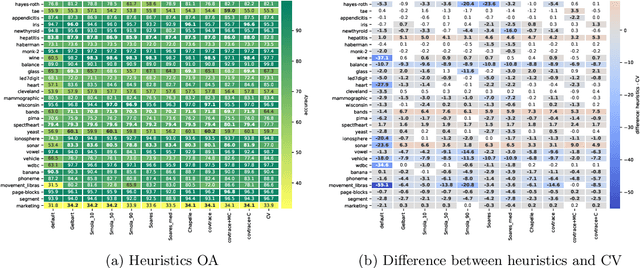
Support Vector Machine (SVM) is one of the most popular classification methods, and a de-facto reference for many Machine Learning approaches. Its performance is determined by parameter selection, which is usually achieved by a time-consuming grid search cross-validation procedure. There exist, however, several unsupervised heuristics that take advantage of the characteristics of the dataset for selecting parameters instead of using class label information. Unsupervised heuristics, while an order of magnitude faster, are scarcely used under the assumption that their results are significantly worse than those of grid search. To challenge that assumption we have conducted a wide study of various heuristics for SVM parameter selection on over thirty datasets, in both supervised and semi-supervised scenarios. In most cases, the cross-validation grid search did not achieve a significant advantage over the heuristics. In particular, heuristical parameter selection may be preferable for high dimensional and unbalanced datasets or when a small number of examples is available. Our results also show that using a heuristic to determine the starting point of further cross-validation does not yield significantly better results than the default start.