 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Artificial Intelligence to Combat Online Hate: Exploring the Challenges and Opportunities of Large Language Models in Hate Speech Detection
Paper and Code
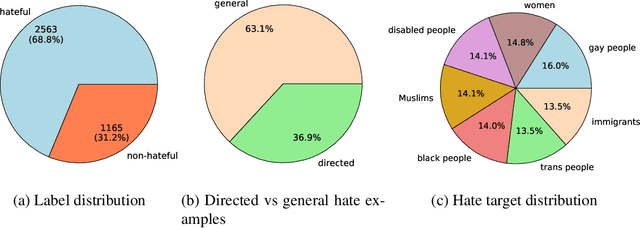
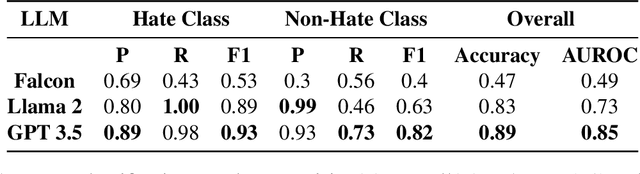

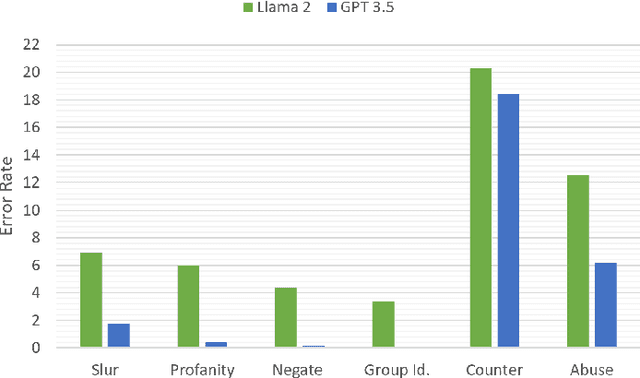
Large language models (LLMs) excel in many diverse applications beyond language generation, e.g., translation, summarization, and sentiment analysis. One intriguing application is in text classification. This becomes pertinent in the realm of identifying hateful or toxic speech -- a domain fraught with challenges and ethical dilemmas. In our study, we have two objectives: firstly, to offer a literature review revolving around LLMs as classifiers, emphasizing their role in detecting and classifying hateful or toxic content. Subsequently, we explore the efficacy of several LLMs in classifying hate speech: identifying which LLMs excel in this task as well as their underlying attributes and training. Providing insight into the factors that contribute to an LLM proficiency (or lack thereof) in discerning hateful content. By combining a comprehensive literature review with an empirical analysis, our paper strives to shed light on the capabilities and constraints of LLMs in the crucial domain of hate speech detection.