 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrid Search Hyperparameter Benchmarking of BERT, ALBERT, and LongFormer on DuoRC
Paper and Code

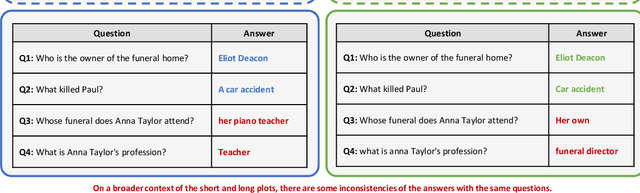
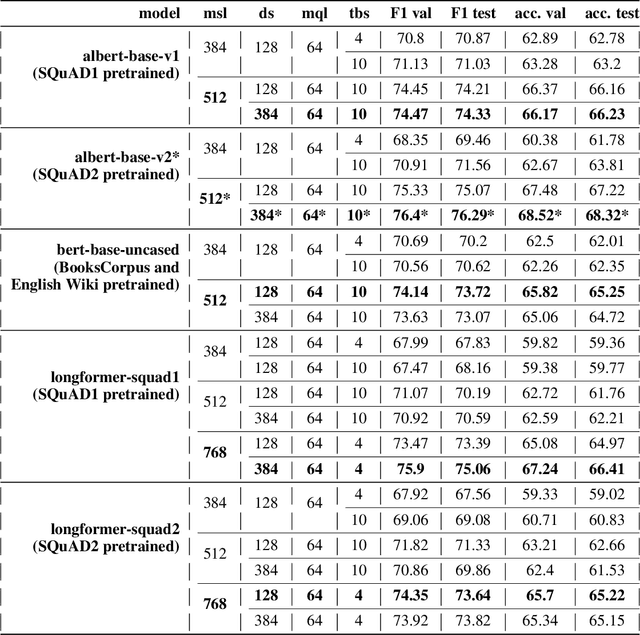
The purpose of this project is to evaluate three language models named BERT, ALBERT, and LongFormer on the Question Answering dataset called DuoRC. The language model task has two inputs, a question, and a context. The context is a paragraph or an entire document while the output is the answer based on the context. The goal is to perform grid search hyperparameter fine-tuning using DuoRC. Pretrained weights of the models are taken from the Huggingface library. Different sets of hyperparameters are used to fine-tune the models using two versions of DuoRC which are the SelfRC and the ParaphraseRC. The results show that the ALBERT (pretrained using the SQuAD1 dataset) has an F1 score of 76.4 and an accuracy score of 68.52 after fine-tuning on the SelfRC dataset. The Longformer model (pretrained using the SQuAD and SelfRC datasets) has an F1 score of 52.58 and an accuracy score of 46.60 after fine-tuning on the ParaphraseRC dataset. The current results outperformed the results from the previous model by DuoRC.