 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Based Machine Learning Improves Just-in-Time Defect Prediction
Paper and Code
Oct 11, 2021

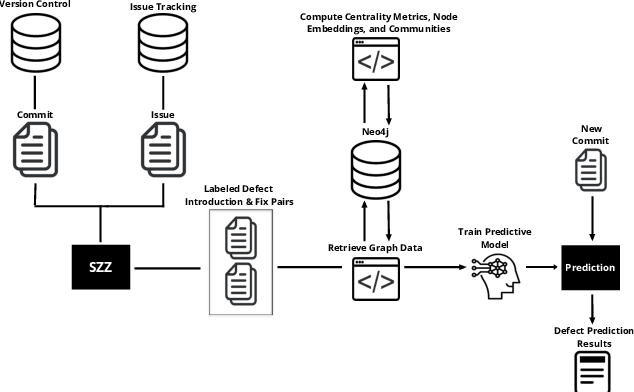

The increasing complexity of today's software requires the contribution of thousands of developers. This complex collaboration structure makes developers more likely to introduce defect-prone changes that lead to software faults. Determining when these defect-prone changes are introduced has proven challenging, and using traditional machine learning (ML) methods to make these determinations seems to have reached a plateau. In this work, we build contribution graphs consisting of developers and source files to capture the nuanced complexity of changes required to build software. By leveraging these contribution graphs, our research shows the potential of using graph-based ML to improve Just-In-Time (JIT) defect prediction. We hypothesize that features extracted from the contribution graphs may be better predictors of defect-prone changes than intrinsic features derived from software characteristics. We corroborate our hypothesis using graph-based ML for classifying edges that represent defect-prone changes. This new framing of the JIT defect prediction problem leads to remarkably better results. We test our approach on 14 open-source projects and show that our best model can predict whether or not a code change will lead to a defect with an F1 score as high as 86.25$\%$. This represents an increase of as much as 55.4$\%$ over the state-of-the-art in JIT defect prediction. We describe limitations, open challenges, and how this method can be used for operational JIT defect prediction.