 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Based Language Model Red Teaming
Paper and Code
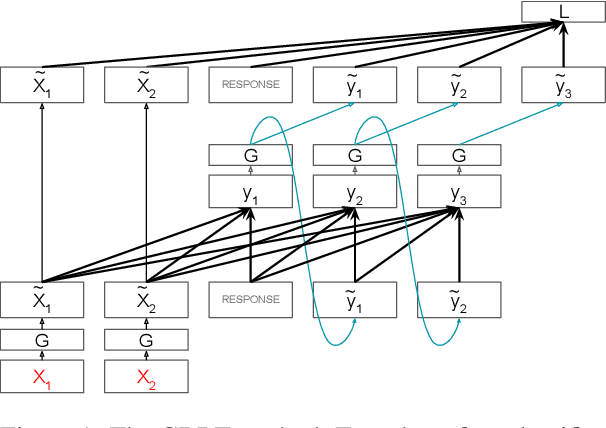

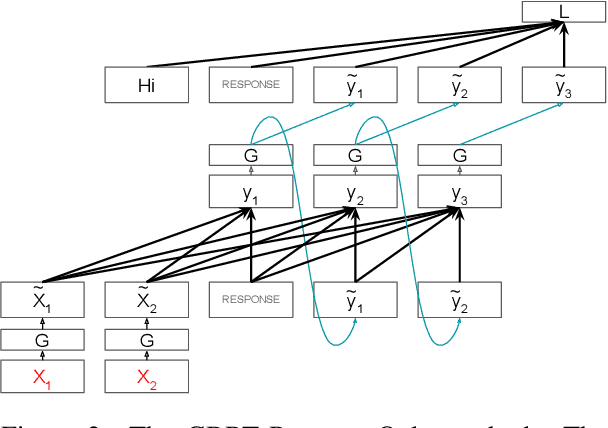
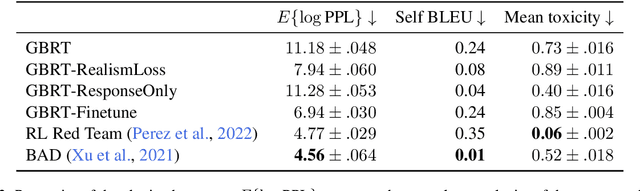
Red teaming is a common strategy for identifying weaknesses in generative language models (LMs), where adversarial prompts are produced that trigger an LM to generate unsafe responses. Red teaming is instrumental for both model alignment and evaluation, but is labor-intensive and difficult to scale when done by humans. In this paper, we present Gradient-Based Red Teaming (GBRT), a red teaming method for automatically generating diverse prompts that are likely to cause an LM to output unsafe responses. GBRT is a form of prompt learning, trained by scoring an LM response with a safety classifier and then backpropagating through the frozen safety classifier and LM to update the prompt. To improve the coherence of input prompts, we introduce two variants that add a realism loss and fine-tune a pretrained model to generate the prompts instead of learning the prompts directly. Our experiments show that GBRT is more effective at finding prompts that trigger an LM to generate unsafe responses than a strong reinforcement learning-based red teaming approach, and succeeds even when the LM has been fine-tuned to produce safer outputs.