Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGOBO: Quantizing Attention-Based NLP Models for Low Latency and Energy Efficient Inference
Paper and Code
May 08, 2020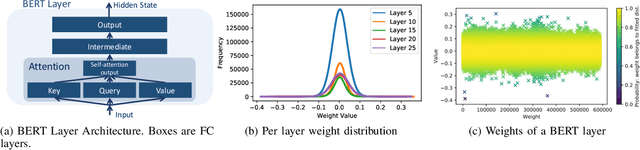
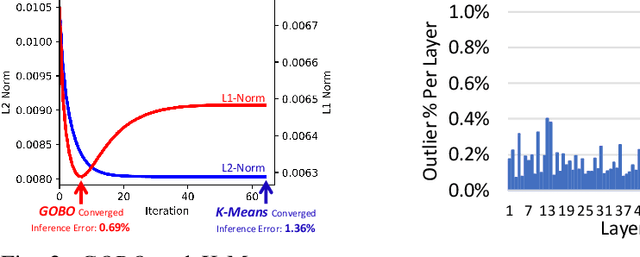


Attention-based models have demonstrated remarkable success in various natural language understanding tasks. However, efficient execution remains a challenge for these models which are memory-bound due to their massive number of parameters. We present a model quantization technique that compresses the vast majority (typically 99.9%) of the 32-bit floating-point parameters of state-of-the-art BERT models and its variants to 3 bits while maintaining their accuracy. Unlike other quantization methods, our technique does not require fine-tuning nor retraining to compensate for the quantization error.
View paper on