 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLoD: Composing Global Contexts and Local Details in Image Generation
Paper and Code
Apr 23, 2024
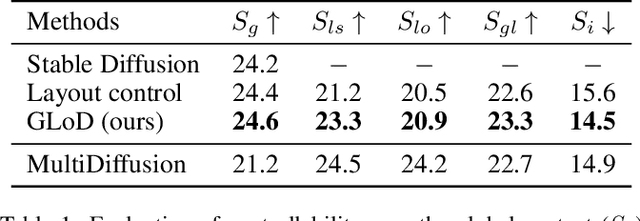
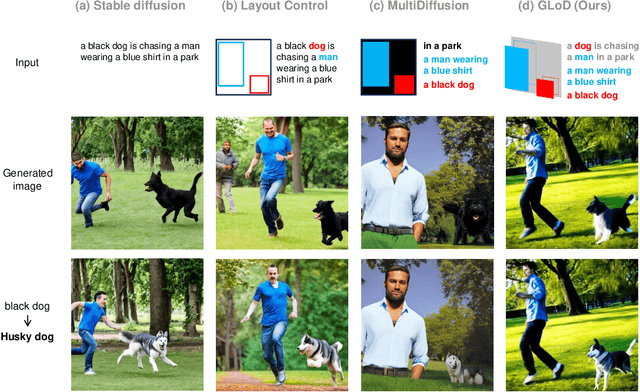
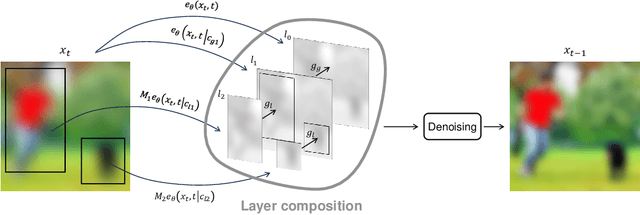
Diffusion models have demonstrated their capability to synthesize high-quality and diverse images from textual prompts. However, simultaneous control over both global contexts (e.g., object layouts and interactions) and local details (e.g., colors and emotions) still remains a significant challenge. The models often fail to understand complex descriptions involving multiple objects and reflect specified visual attributes to wrong targets or ignore them. This paper presents Global-Local Diffusion (\textit{GLoD}), a novel framework which allows simultaneous control over the global contexts and the local details in text-to-image generation without requiring training or fine-tuning. It assigns multiple global and local prompts to corresponding layers and composes their noises to guide a denoising process using pre-trained diffusion models. Our framework enables complex global-local compositions, conditioning objects in the global prompt with the local prompts while preserving other unspecified identities. Our quantitative and qualitative evaluations demonstrate that GLoD effectively generates complex images that adhere to both user-provided object interactions and object details.