 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobally Consistent Video Depth and Pose Estimation with Efficient Test-Time Training
Paper and Code
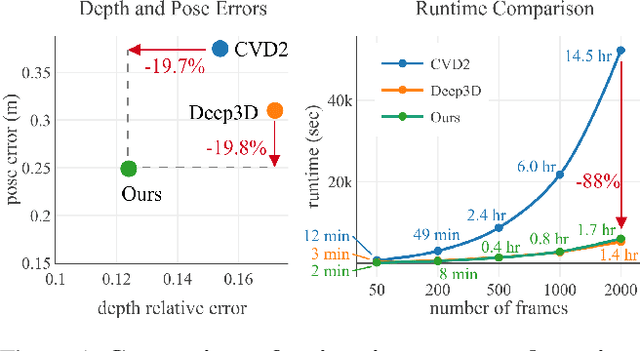
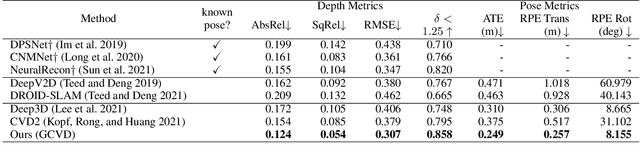


Dense depth and pose estimation is a vital prerequisite for various video applications. Traditional solutions suffer from the robustness of sparse feature tracking and insufficient camera baselines in videos. Therefore, recent methods utilize learning-based optical flow and depth prior to estimate dense depth. However, previous works require heavy computation time or yield sub-optimal depth results. We present GCVD, a globally consistent method for learning-based video structure from motion (SfM) in this paper. GCVD integrates a compact pose graph into the CNN-based optimization to achieve globally consistent estimation from an effective keyframe selection mechanism. It can improve the robustness of learning-based methods with flow-guided keyframes and well-established depth prior. Experimental results show that GCVD outperforms the state-of-the-art methods on both depth and pose estimation. Besides, the runtime experiments reveal that it provides strong efficiency in both short- and long-term videos with global consistency provided.