 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenetic Instruct: Scaling up Synthetic Generation of Coding Instructions for Large Language Models
Paper and Code

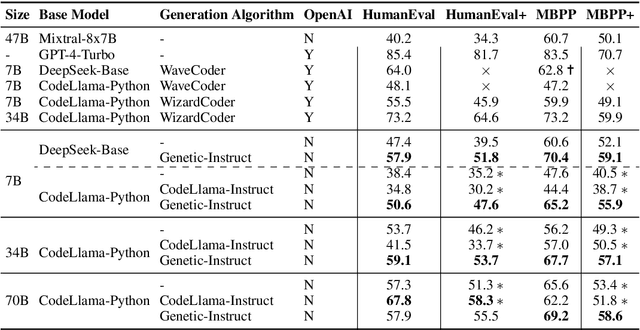
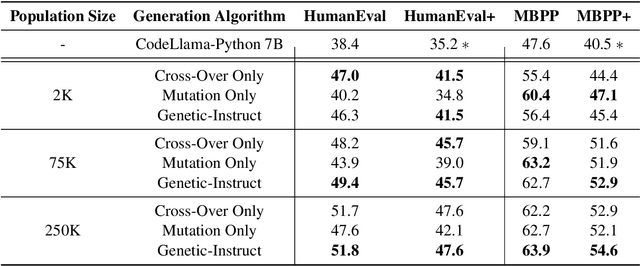

Large Language Models (LLMs) rely on instruction samples for alignment, but creating these datasets poses challenges, particularly in expert-dependent tasks like coding, which can be cost-prohibitive. One approach to mitigate these challenges is synthesizing data using another LLM. In this paper, we introduce a scalable method for generating synthetic instructions to enhance the code generation capability of LLMs. The proposed algorithm, Genetic-Instruct, mimics evolutionary processes, utilizing self-instruction to create numerous synthetic samples from a limited number of seeds. Genetic-Instruct is designed for efficient scaling of the generation process. Fine-tuning multiple coding LLMs with the synthetic samples demonstrates a significant improvement in their code generation accuracy compared to the baselines.