 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Transformers
Paper and Code

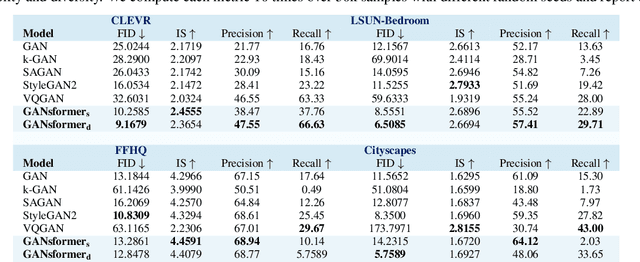
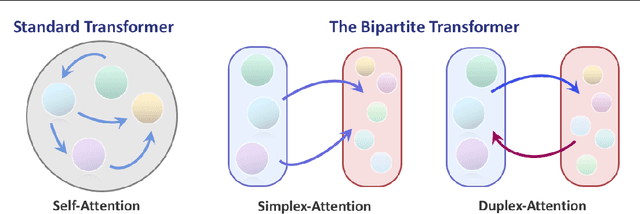
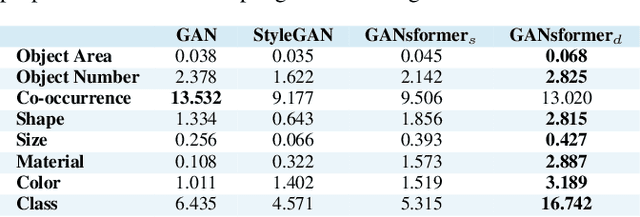
We introduce the GANsformer, a novel and efficient type of transformer, and explore it for the task of visual generative modeling. The network employs a bipartite structure that enables long-range interactions across the image, while maintaining computation of linearly efficiency, that can readily scale to high-resolution synthesis. It iteratively propagates information from a set of latent variables to the evolving visual features and vice versa, to support the refinement of each in light of the other and encourage the emergence of compositional representations of objects and scenes. In contrast to the classic transformer architecture, it utilizes multiplicative integration that allows flexible region-based modulation, and can thus be seen as a generalization of the successful StyleGAN network. We demonstrate the model's strength and robustness through a careful evaluation over a range of datasets, from simulated multi-object environments to rich real-world indoor and outdoor scenes, showing it achieves state-of-the-art results in terms of image quality and diversity, while enjoying fast learning and better data-efficiency. Further qualitative and quantitative experiments offer us an insight into the model's inner workings, revealing improved interpretability and stronger disentanglement, and illustrating the benefits and efficacy of our approach. An implementation of the model is available at https://github.com/dorarad/gansformer.