 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Media Background Checks for Automated Source Critical Reasoning
Paper and Code


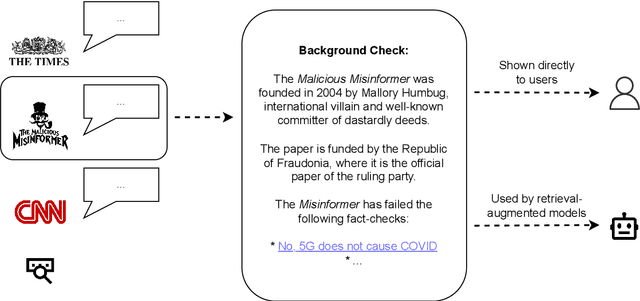
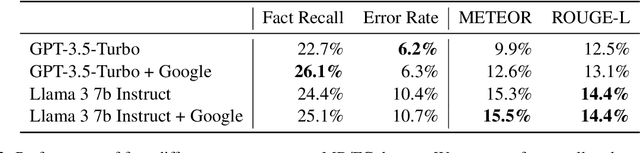
Not everything on the internet is true. This unfortunate fact requires both humans and models to perform complex reasoning about credibility when working with retrieved information. In NLP, this problem has seen little attention. Indeed, retrieval-augmented models are not typically expected to distrust retrieved documents. Human experts overcome the challenge by gathering signals about the context, reliability, and tendency of source documents - that is, they perform source criticism. We propose a novel NLP task focused on finding and summarising such signals. We introduce a new dataset of 6,709 "media background checks" derived from Media Bias / Fact Check, a volunteer-run website documenting media bias. We test open-source and closed-source LLM baselines with and without retrieval on this dataset, finding that retrieval greatly improves performance. We furthermore carry out human evaluation, demonstrating that 1) media background checks are helpful for humans, and 2) media background checks are helpful for retrieval-augmented models.