 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing in the Real World with Representation Learning
Paper and Code
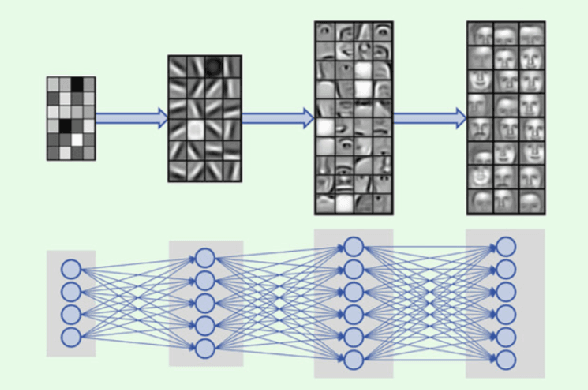
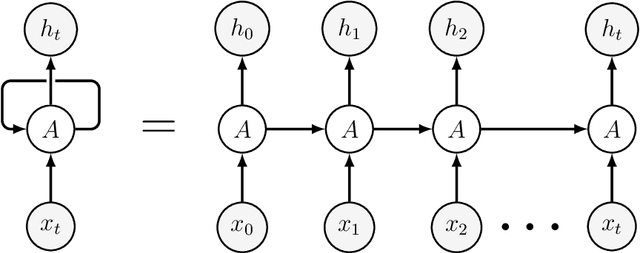
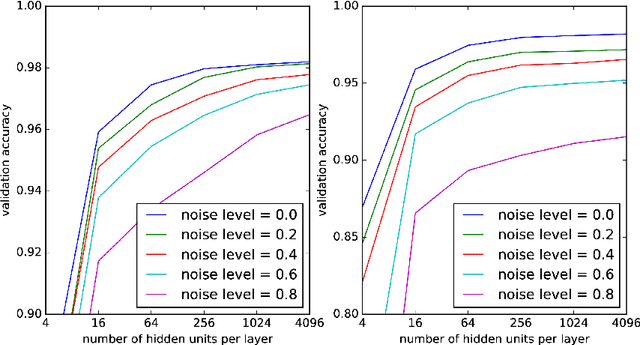
Machine learning (ML) formalizes the problem of getting computers to learn from experience as optimization of performance according to some metric(s) on a set of data examples. This is in contrast to requiring behaviour specified in advance (e.g. by hard-coded rules). Formalization of this problem has enabled great progress in many applications with large real-world impact, including translation, speech recognition, self-driving cars, and drug discovery. But practical instantiations of this formalism make many assumptions - for example, that data are i.i.d.: independent and identically distributed - whose soundness is seldom investigated. And in making great progress in such a short time, the field has developed many norms and ad-hoc standards, focused on a relatively small range of problem settings. As applications of ML, particularly in artificial intelligence (AI) systems, become more pervasive in the real world, we need to critically examine these assumptions, norms, and problem settings, as well as the methods that have become de-facto standards. There is much we still do not understand about how and why deep networks trained with stochastic gradient descent are able to generalize as well as they do, why they fail when they do, and how they will perform on out-of-distribution data. In this thesis I cover some of my work towards better understanding deep net generalization, identify several ways assumptions and problem settings fail to generalize to the real world, and propose ways to address those failures in practice.