 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGap-Filling Prompting Enhances Code-Assisted Mathematical Reasoning
Paper and Code

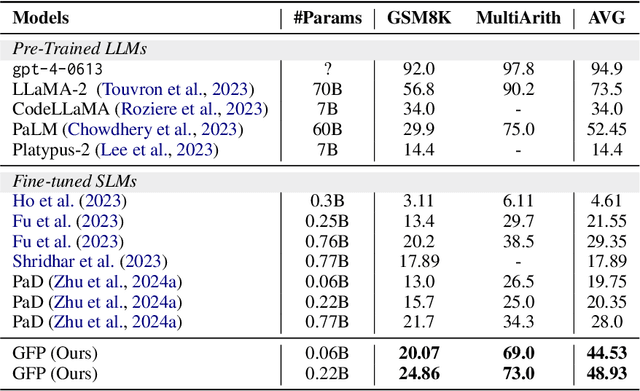
Despite the strong performance of large language models (LLMs) in tasks like mathematical reasoning, their practical use is limited by high computational demands and proprietary restrictions. Chain-of-thought (CoT) and program-of-thought (PoT) fine-tuning are common methods to transfer LLM knowledge to small language models (SLMs). However, CoT often leads to calculation errors in SLMs, while PoT has shown more promise. While most PoT-based approaches focus on direct problem-to-code conversion or extracting only the key information from questions and then providing code solution for it, this work emphasizes filling the gaps in the question to clearly illustrate the solution path, which can be challenging for an SLM to understand when such information is not explicitly provided. Therefore, this paper introduces Gap-Filling Prompting (GFP), a novel two-step prompting strategy designed to enhance the problem-solving process for SLMs. The first step identifies these gaps and provides hints for filling them, while the second step adds the hints to the question to generate a final code solution. Experimental results on two benchmark datasets demonstrate that GFP significantly improves the mathematical reasoning abilities of SLMs.