 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Thumbnails to Summaries - A single Deep Neural Network to Rule Them All
Paper and Code
Aug 01, 2018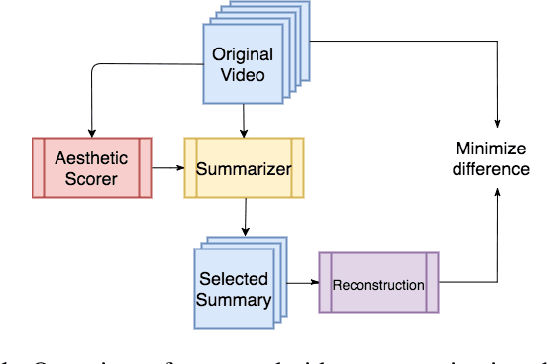
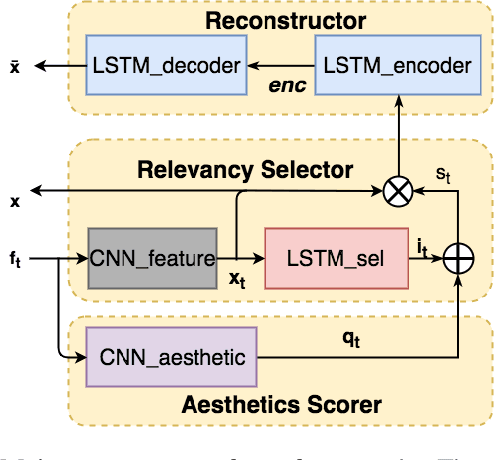
Video summaries come in many forms, from traditional single-image thumbnails, animated thumbnails, storyboards, to trailer-like video summaries. Content creators use the summaries to display the most attractive portion of their videos; the users use them to quickly evaluate if a video is worth watching. All forms of summaries are essential to video viewers, content creators, and advertisers. Often video content management systems have to generate multiple versions of summaries that vary in duration and presentational forms. We present a framework ReconstSum that utilizes LSTM-based autoencoder architecture to extract and select a sparse subset of video frames or keyshots that optimally represent the input video in an unsupervised manner. The encoder selects a subset from the input video while the decoder seeks to reconstruct the video from the selection. The goal is to minimize the difference between the original input video and the reconstructed video. Our method is easily extendable to generate a variety of applications including static video thumbnails, animated thumbnails, storyboards and "trailer-like" highlights. We specifically study and evaluate two most popular use cases: thumbnail generation and storyboard generation. We demonstrate that our methods generate better results than the state-of-the-art techniques in both use cases.