 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Patch to Image Segmentation using Fully Convolutional Networks - Application to Retinal Images
Paper and Code
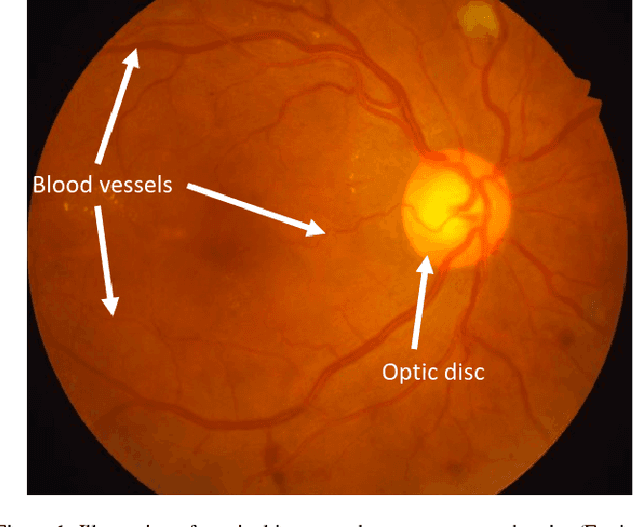


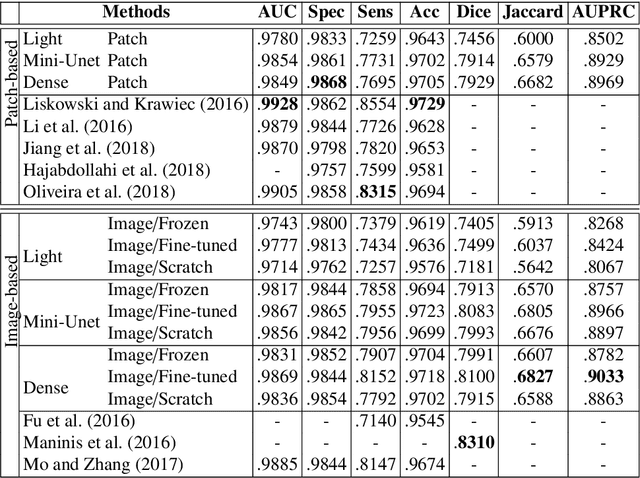
In general, deep learning based models require a tremendous amount of samples for appropriate training, which is difficult to satisfy in the medical field. This issue can usually be avoided with a proper initialization of the weights. On the task of medical image segmentation in general, two techniques are usually employed to tackle the training of a deep network $f_T$. The first one consists in reusing some weights of a network $f_S$ pre-trained on a large scale database ($e.g.$ ImageNet). This procedure, also known as \textit{transfer learning}, happens to reduce the flexibility when it comes to new network design since $f_T$ is constrained to match some parts of $f_S$. The second commonly used technique consists in working on image patches to benefit from the large number of available patches. This paper brings together these two techniques and propose to train arbitrarily designed networks, with a focus on relatively small databases, in two stages: patch pre-training and full sized image fine-tuning. An experimental work have been carried out on the tasks of retinal blood vessel segmentation and the optic disc one, using four publicly available databases. Furthermore, three types of network are considered, going from a very light weighted network to a densely connected one. The final results show the efficiency of the proposed framework along with state of the art results on all the databases.