Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Once Upon a Time to Happily Ever After: Tracking Emotions in Novels and Fairy Tales
Paper and Code
Sep 23, 2013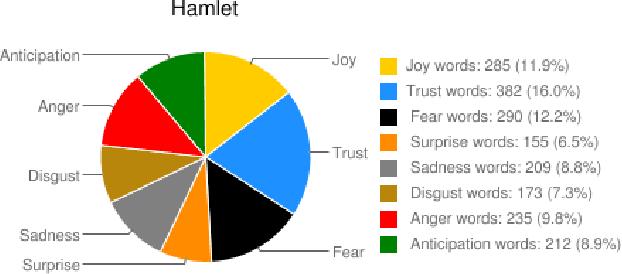

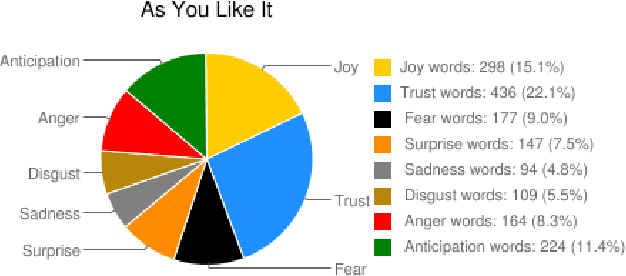

Today we have access to unprecedented amounts of literary texts. However, search still relies heavily on key words. In this paper, we show how sentiment analysis can be used in tandem with effective visualizations to quantify and track emotions in both individual books and across very large collections. We introduce the concept of emotion word density, and using the Brothers Grimm fairy tales as example, we show how collections of text can be organized for better search. Using the Google Books Corpus we show how to determine an entity's emotion associations from co-occurring words. Finally, we compare emotion words in fairy tales and novels, to show that fairy tales have a much wider range of emotion word densities than novels.
* In Proceedings of the ACL Workshop on Language Technology for
Cultural Heritage, Social Sciences, and Humanities (LaTeCH), 2011, Portland,
OR
View paper on