 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalizing and Estimating Distribution Inference Risks
Paper and Code

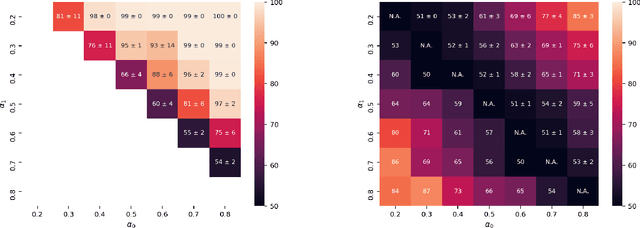

Property inference attacks reveal statistical properties about a training set but are difficult to distinguish from the intrinsic purpose of statistical machine learning, namely to produce models that capture statistical properties about a distribution. Motivated by Yeom et al.'s membership inference framework, we propose a formal and general definition of property inference attacks. The proposed notion describes attacks that can distinguish between possible training distributions, extending beyond previous property inference attacks that infer the ratio of a particular type of data in the training data set such as the proportion of females. We show how our definition captures previous property inference attacks as well as a new attack that can reveal the average node degree or clustering coefficient of a training graph. Our definition also enables a theorem that connects the maximum possible accuracy of inference attacks distinguishing between distributions to the effective size of dataset leaked by the model. To quantify and understand property inference risks, we conduct a series of experiments across a range of different distributions using both black-box and white-box attacks. Our results show that inexpensive attacks are often as effective as expensive meta-classifier attacks, and that there are surprising asymmetries in the effectiveness of attacks. We also extend the state-of-the-art property inference attack to work on convolutional neural networks, and propose techniques to help identify parameters in a model that leak the most information, thus significantly lowering resource requirements for meta-classifier attacks.