 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForm2Seq : A Framework for Higher-Order Form Structure Extraction
Paper and Code
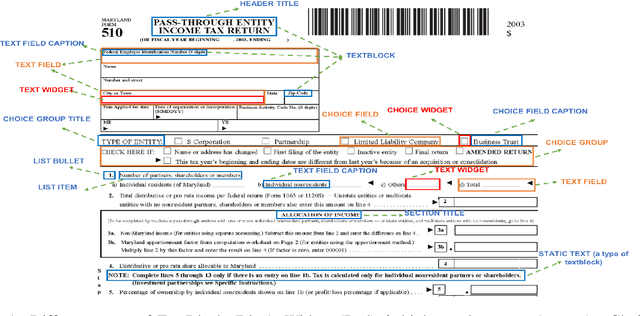
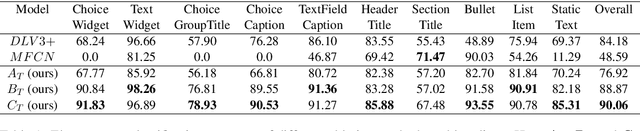
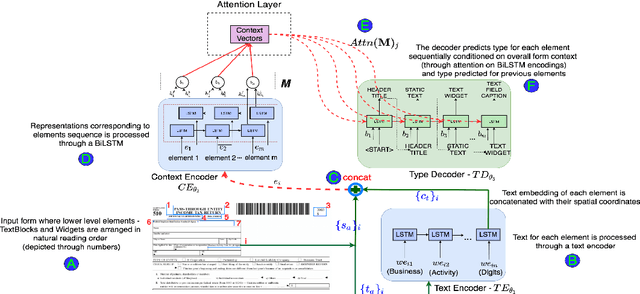
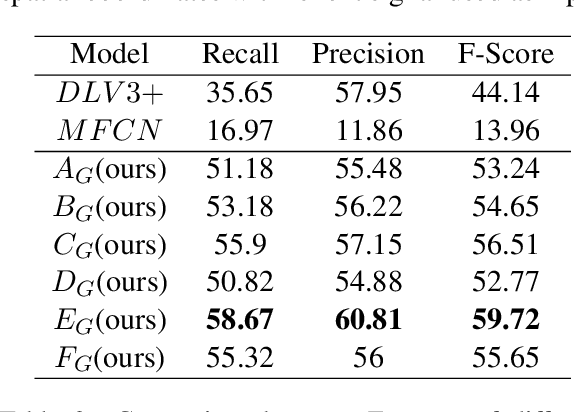
Document structure extraction has been a widely researched area for decades with recent works performing it as a semantic segmentation task over document images using fully-convolution networks. Such methods are limited by image resolution due to which they fail to disambiguate structures in dense regions which appear commonly in forms. To mitigate this, we propose Form2Seq, a novel sequence-to-sequence (Seq2Seq) inspired framework for structure extraction using text, with a specific focus on forms, which leverages relative spatial arrangement of structures. We discuss two tasks; 1) Classification of low-level constituent elements (TextBlock and empty fillable Widget) into ten types such as field captions, list items, and others; 2) Grouping lower-level elements into higher-order constructs, such as Text Fields, ChoiceFields and ChoiceGroups, used as information collection mechanism in forms. To achieve this, we arrange the constituent elements linearly in natural reading order, feed their spatial and textual representations to Seq2Seq framework, which sequentially outputs prediction of each element depending on the final task. We modify Seq2Seq for grouping task and discuss improvements obtained through cascaded end-to-end training of two tasks versus training in isolation. Experimental results show the effectiveness of our text-based approach achieving an accuracy of 90% on classification task and an F1 of 75.82, 86.01, 61.63 on groups discussed above respectively, outperforming segmentation baselines. Further we show our framework achieves state of the results for table structure recognition on ICDAR 2013 dataset.