 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFISHDBC: Flexible, Incremental, Scalable, Hierarchical Density-Based Clustering for Arbitrary Data and Distance
Paper and Code

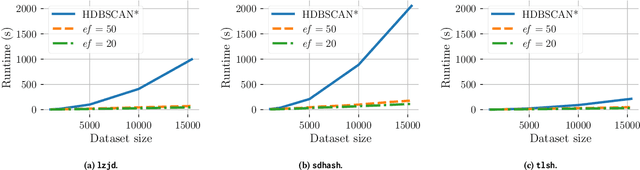


FISHDBC is a flexible, incremental, scalable, and hierarchical density-based clustering algorithm. It is flexible because it empowers users to work on arbitrary data, skipping the feature extraction step that usually transforms raw data in numeric arrays letting users define an arbitrary distance function instead. It is incremental and scalable: it avoids the $\mathcal O(n^2)$ performance of other approaches in non-metric spaces and requires only lightweight computation to update the clustering when few items are added. It is hierarchical: it produces a "flat" clustering which can be expanded to a tree structure, so that users can group and/or divide clusters in sub- or super-clusters when data exploration requires so. It is density-based and approximates HDBSCAN*, an evolution of DBSCAN.