 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Learning via Dependency Maximization and Instance Discriminant Analysis
Paper and Code
Sep 07, 2021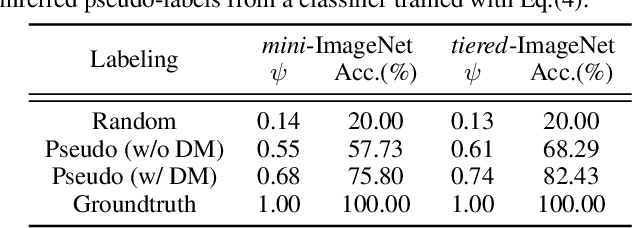
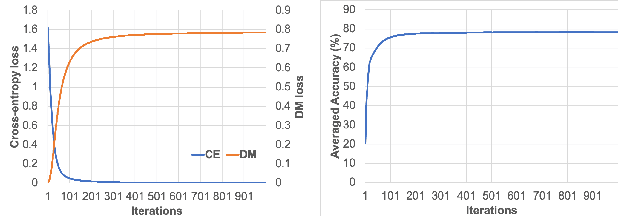
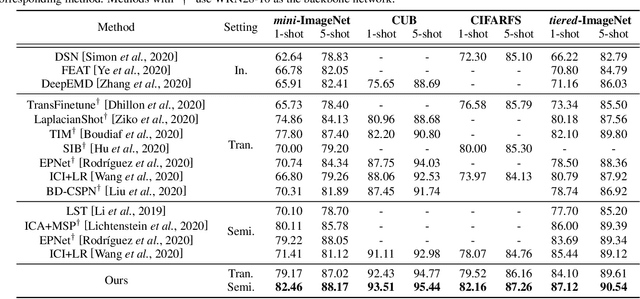
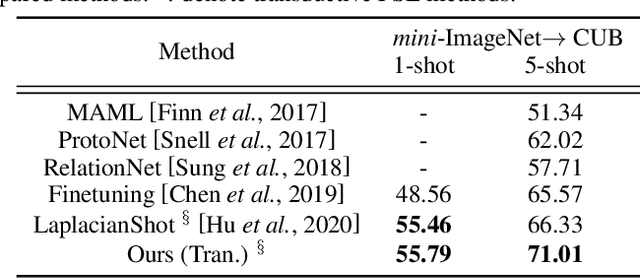
We study the few-shot learning (FSL) problem, where a model learns to recognize new objects with extremely few labeled training data per category. Most of previous FSL approaches resort to the meta-learning paradigm, where the model accumulates inductive bias through learning many training tasks so as to solve a new unseen few-shot task. In contrast, we propose a simple approach to exploit unlabeled data accompanying the few-shot task for improving few-shot performance. Firstly, we propose a Dependency Maximization method based on the Hilbert-Schmidt norm of the cross-covariance operator, which maximizes the statistical dependency between the embedded feature of those unlabeled data and their label predictions, together with the supervised loss over the support set. We then use the obtained model to infer the pseudo-labels for those unlabeled data. Furthermore, we propose anInstance Discriminant Analysis to evaluate the credibility of each pseudo-labeled example and select the most faithful ones into an augmented support set to retrain the model as in the first step. We iterate the above process until the pseudo-labels for the unlabeled data becomes stable. Following the standard transductive and semi-supervised FSL setting, our experiments show that the proposed method out-performs previous state-of-the-art methods on four widely used benchmarks, including mini-ImageNet, tiered-ImageNet, CUB, and CIFARFS.