 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Normalisation for Robust Speech Recognition
Paper and Code
Jul 14, 2015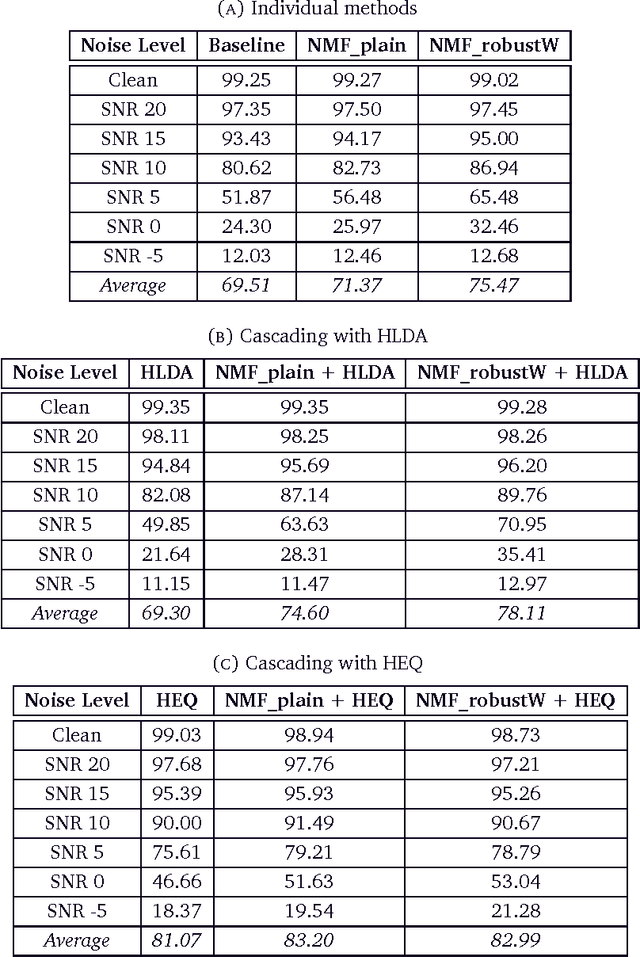
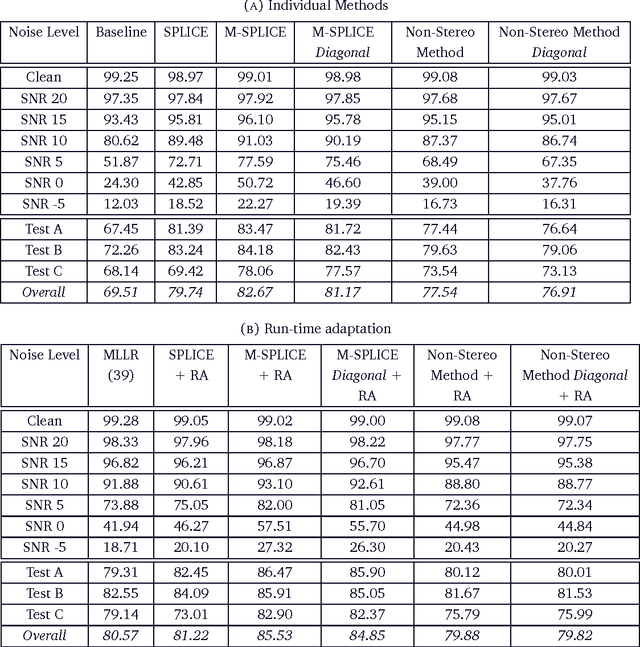

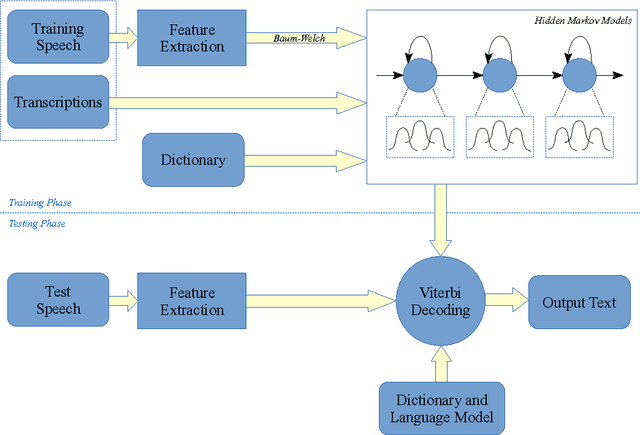
Speech recognition system performance degrades in noisy environments. If the acoustic models are built using features of clean utterances, the features of a noisy test utterance would be acoustically mismatched with the trained model. This gives poor likelihoods and poor recognition accuracy. Model adaptation and feature normalisation are two broad areas that address this problem. While the former often gives better performance, the latter involves estimation of lesser number of parameters, making the system feasible for practical implementations. This research focuses on the efficacies of various subspace, statistical and stereo based feature normalisation techniques. A subspace projection based method has been investigated as a standalone and adjunct technique involving reconstruction of noisy speech features from a precomputed set of clean speech building-blocks. The building blocks are learned using non-negative matrix factorisation (NMF) on log-Mel filter bank coefficients, which form a basis for the clean speech subspace. The work provides a detailed study on how the method can be incorporated into the extraction process of Mel-frequency cepstral coefficients. Experimental results show that the new features are robust to noise, and achieve better results when combined with the existing techniques. The work also proposes a modification to the training process of SPLICE algorithm for noise robust speech recognition. It is based on feature correlations, and enables this stereo-based algorithm to improve the performance in all noise conditions, especially in unseen cases. Further, the modified framework is extended to work for non-stereo datasets where clean and noisy training utterances, but not stereo counterparts, are required. An MLLR-based computationally efficient run-time noise adaptation method in SPLICE framework has been proposed.