 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature diversity in self-supervised learning
Paper and Code
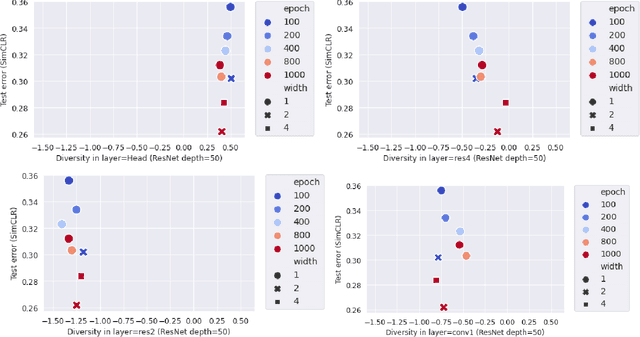
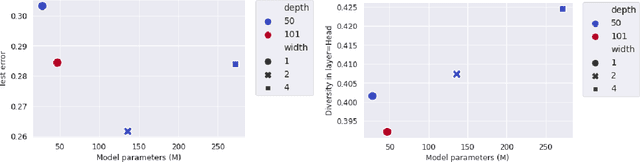
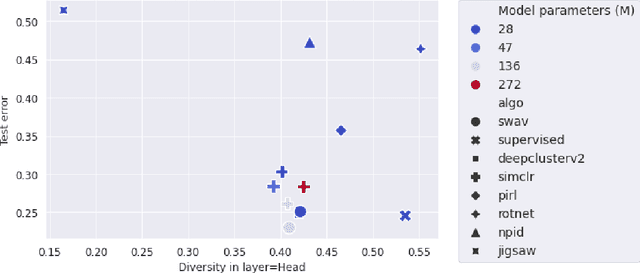
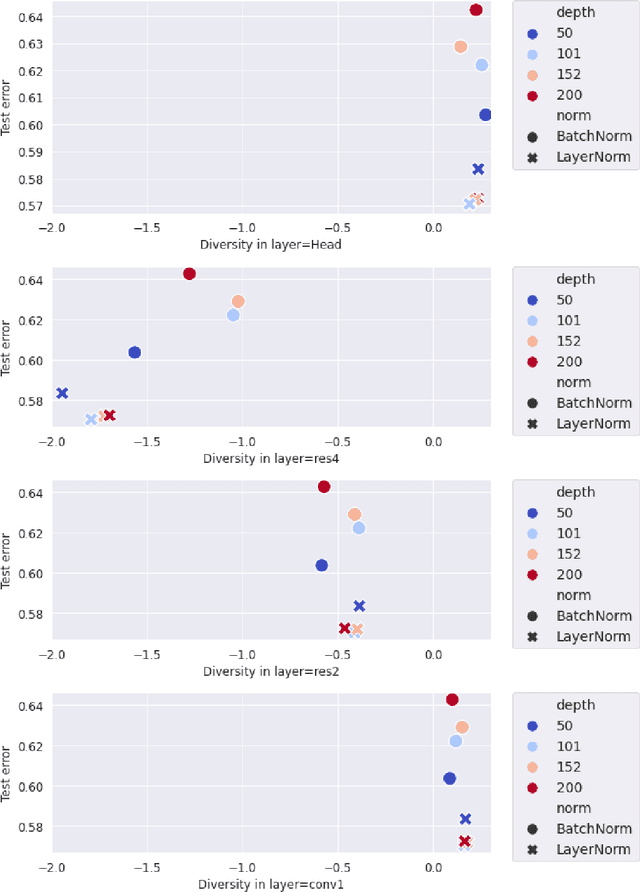
Many studies on scaling laws consider basic factors such as model size, model shape, dataset size, and compute power. These factors are easily tunable and represent the fundamental elements of any machine learning setup. But researchers have also employed more complex factors to estimate the test error and generalization performance with high predictability. These factors are generally specific to the domain or application. For example, feature diversity was primarily used for promoting syn-to-real transfer by Chen et al. (2021). With numerous scaling factors defined in previous works, it would be interesting to investigate how these factors may affect overall generalization performance in the context of self-supervised learning with CNN models. How do individual factors promote generalization, which includes varying depth, width, or the number of training epochs with early stopping? For example, does higher feature diversity result in higher accuracy held in complex settings other than a syn-to-real transfer? How do these factors depend on each other? We found that the last layer is the most diversified throughout the training. However, while the model's test error decreases with increasing epochs, its diversity drops. We also discovered that diversity is directly related to model width.