 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastContext: an efficient and scalable implementation of the ConText algorithm
Paper and Code
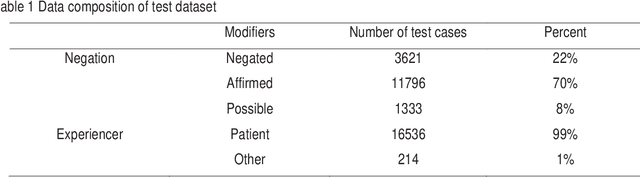
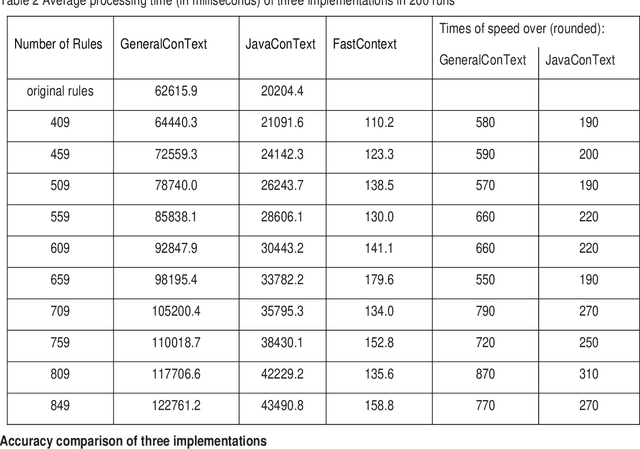
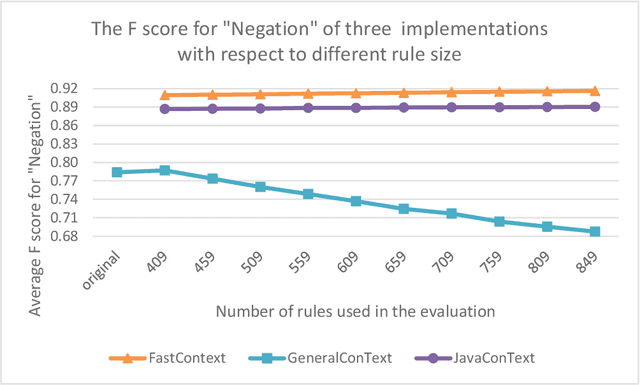
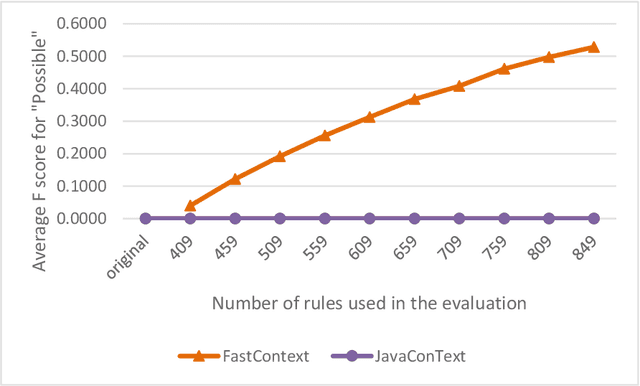
Objective: To develop and evaluate FastContext, an efficient, scalable implementation of the ConText algorithm suitable for very large-scale clinical natural language processing. Background: The ConText algorithm performs with state-of-art accuracy in detecting the experiencer, negation status, and temporality of concept mentions in clinical narratives. However, the speed limitation of its current implementations hinders its use in big data processing. Methods: We developed FastContext through hashing the ConText's rules, then compared its speed and accuracy with JavaConText and GeneralConText, two widely used Java implementations. Results: FastContext ran two orders of magnitude faster and was less decelerated by rule increase than the other two implementations used in this study for comparison. Additionally, FastContext consistently gained accuracy improvement as the rules increased (the desired outcome of adding new rules), while the other two implementations did not. Conclusions: FastContext is an efficient, scalable implementation of the popular ConText algorithm, suitable for natural language applications on very large clinical corpora.