 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Interactive Video Object Segmentation with Graph Neural Networks
Paper and Code
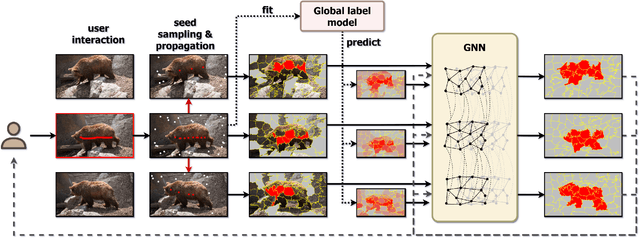


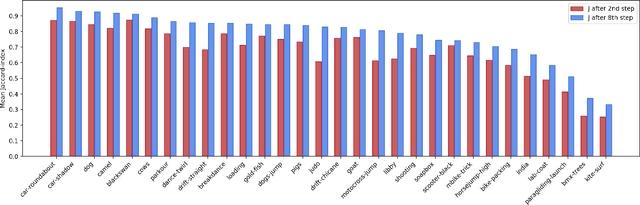
Pixelwise annotation of image sequences can be very tedious for humans. Interactive video object segmentation aims to utilize automatic methods to speed up the process and reduce the workload of the annotators. Most contemporary approaches rely on deep convolutional networks to collect and process information from human annotations throughout the video. However, such networks contain millions of parameters and need huge amounts of labeled training data to avoid overfitting. Beyond that, label propagation is usually executed as a series of frame-by-frame inference steps, which is difficult to be parallelized and is thus time consuming. In this paper we present a graph neural network based approach for tackling the problem of interactive video object segmentation. Our network operates on superpixel-graphs which allow us to reduce the dimensionality of the problem by several magnitudes. We show, that our network possessing only a few thousand parameters is able to achieve state-of-the-art performance, while inference remains fast and can be trained quickly with very little data.