Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Gradient-Based Inference with Continuous Latent Variable Models in Auxiliary Form
Paper and Code
Jun 04, 2013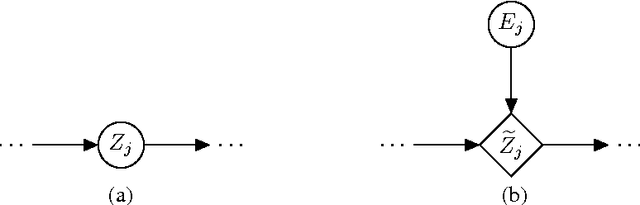
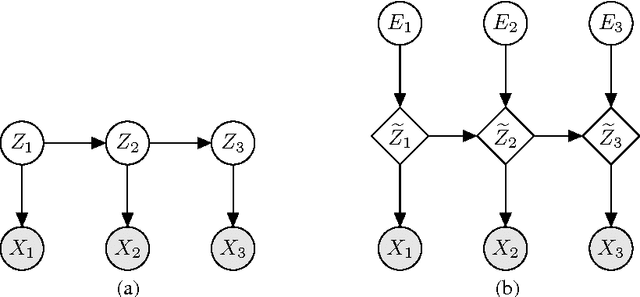

We propose a technique for increasing the efficiency of gradient-based inference and learning in Bayesian networks with multiple layers of continuous latent vari- ables. We show that, in many cases, it is possible to express such models in an auxiliary form, where continuous latent variables are conditionally deterministic given their parents and a set of independent auxiliary variables. Variables of mod- els in this auxiliary form have much larger Markov blankets, leading to significant speedups in gradient-based inference, e.g. rapid mixing Hybrid Monte Carlo and efficient gradient-based optimization. The relative efficiency is confirmed in ex- periments.
View paper on