 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Adjustable Threshold For Uniform Neural Network Quantization
Paper and Code
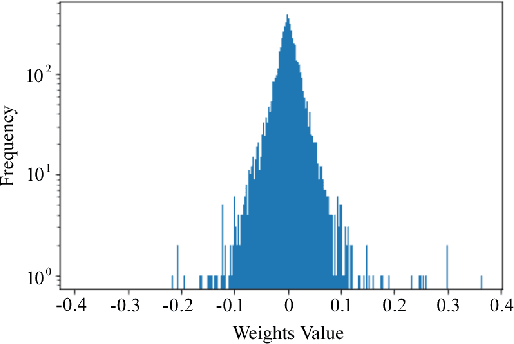
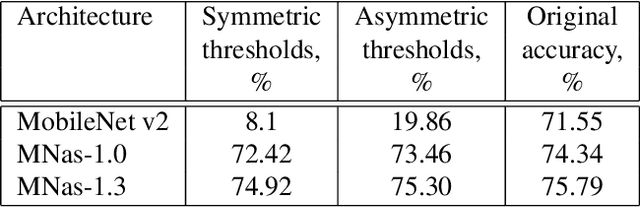
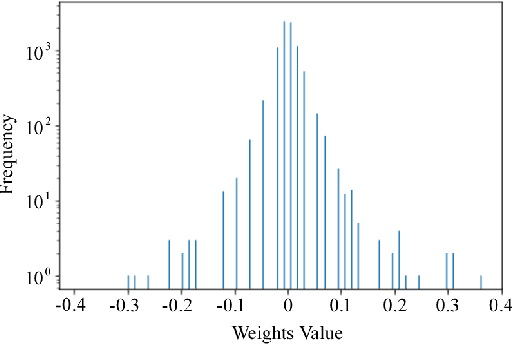
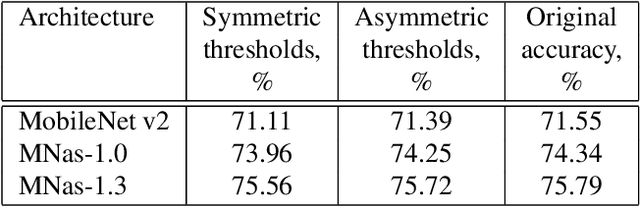
Neural network quantization procedure is the necessary step for porting of neural networks to mobile devices. Quantization allows accelerating the inference, reducing memory consumption and model size. It can be performed without fine-tuning using calibration procedure (calculation of parameters necessary for quantization), or it is possible to train the network with quantization from scratch. Training with quantization from scratch on the labeled data is rather long and resource-consuming procedure. Quantization of network without fine-tuning leads to accuracy drop because of outliers which appear during the calibration. In this article we suggest to simplify the quantization procedure significantly by introducing the trained scale factors for quantization thresholds. It allows speeding up the process of quantization with fine-tuning up to 8 epochs as well as reducing the requirements to the set of train images. By our knowledge, the proposed method allowed us to get the first public available quantized version of MNAS without significant accuracy reduction - 74.8% vs 75.3% for original full-precision network. Model and code are ready for use and available at: https://github.com/agoncharenko1992/FAT-fast_adjustable_threshold.