Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Emotion Recognition
Paper and Code
Jan 26, 2023


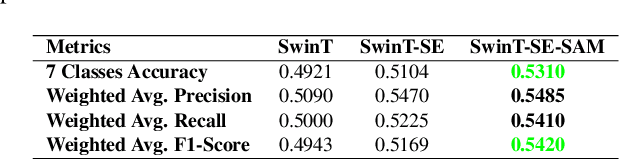
We present a facial emotion recognition framework, built upon Swin vision Transformers jointly with squeeze and excitation block (SE). A transformer model based on an attention mechanism has been presented recently to address vision tasks. Our method uses a vision transformer with a Squeeze excitation block (SE) and sharpness-aware minimizer (SAM). We have used a hybrid dataset, to train our model and the AffectNet dataset to evaluate the result of our model
* arXiv admin note: text overlap with arXiv:2103.14030 by other authors
View paper on