 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Label-specific Key Input Features for Neural Code Intelligence Models
Paper and Code


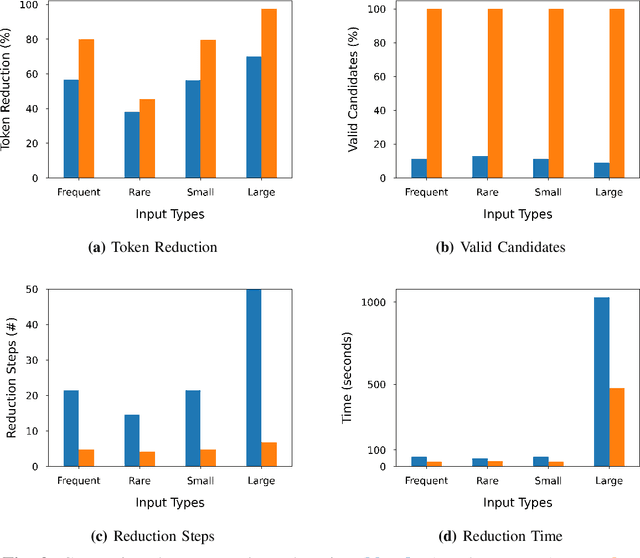
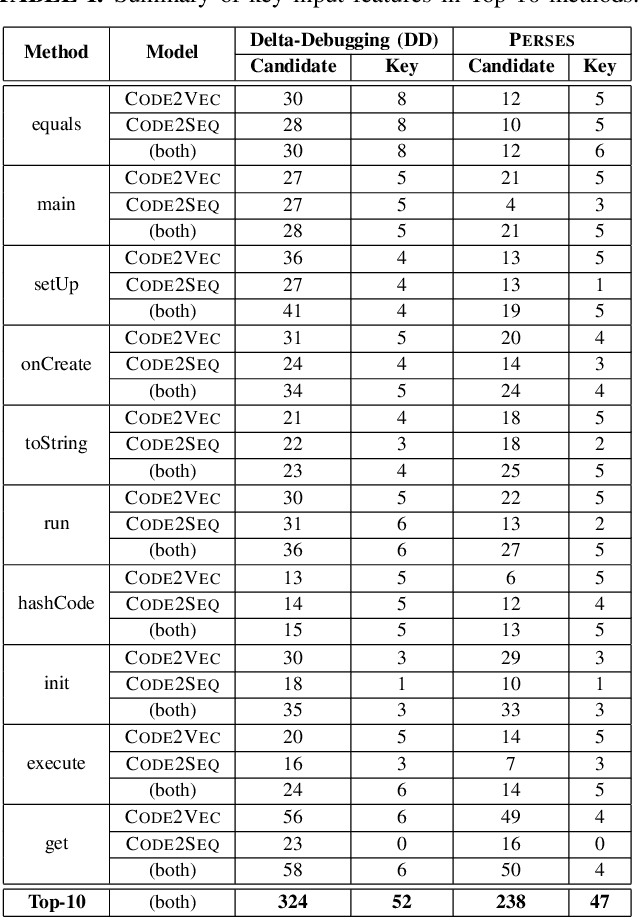
The code intelligence (CI) models are often black-box and do not offer any insights on the input features that they learn for making correct predictions. This opacity may lead to distrust in their prediction and hamper their wider adoption in safety-critical applications. In recent, the program reduction technique is widely being used to identify key input features in order to explain the prediction of CI models. The approach removes irrelevant parts from an input program and keeps the minimal snippets that a CI model needs to maintain its prediction. However, the state-of-the-art approaches mainly use a syntax-unaware program reduction technique that does not follow the syntax of programs, which adds significant overhead to the reduction of input programs and explainability of models. In this paper, we apply a syntax-guided program reduction technique that follows the syntax of input programs during reduction. Our experiments on multiple models across different types of input programs show that the syntax-guided program reduction technique significantly outperforms the syntax-unaware program reduction technique in reducing the size of input programs. Extracting key input features from reduced programs reveals that the syntax-guided reduced programs contain more label-specific key input features and are more vulnerable to adversarial transformation when renaming the key tokens in programs. These label-specific key input features may help to understand the reasoning of models' prediction from different perspectives and increase the trustworthiness to correct classification given by CI models.