 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the influence of fine-tuning data on wav2vec 2.0 model for blind speech quality prediction
Paper and Code
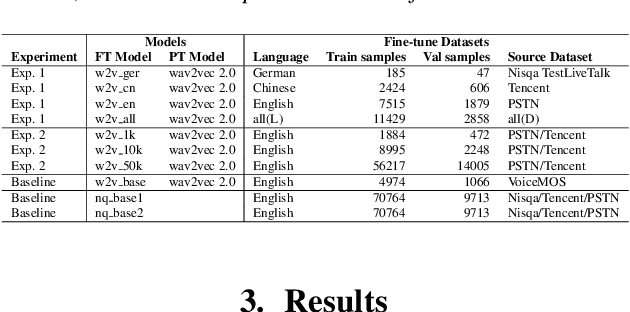


Recent studies have shown how self-supervised models can produce accurate speech quality predictions. Speech representations generated by the pre-trained wav2vec 2.0 model allows constructing robust predicting models using small amounts of annotated data. This opens the possibility of developing strong models in scenarios where labelled data is scarce. It is known that fine-tuning improves the model's performance; however, it is unclear how the data (e.g., language, amount of samples) used for fine-tuning is influencing that performance. In this paper, we explore how using different speech corpus to fine-tune the wav2vec 2.0 can influence its performance. We took four speech datasets containing degradations found in common conferencing applications and fine-tuned wav2vec 2.0 targeting different languages and data size scenarios. The fine-tuned models were tested across all four conferencing datasets plus an additional dataset containing synthetic speech and they were compared against three external baseline models. Results showed that fine-tuned models were able to compete with baseline models. Larger fine-tune data guarantee better performance; meanwhile, diversity in language helped the models deal with specific languages. Further research is needed to evaluate other wav2vec 2.0 models pre-trained with multi-lingual datasets and to develop prediction models that are more resilient to language diversity.