 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Impact of Tunable Agents in Sequential Social Dilemmas
Paper and Code

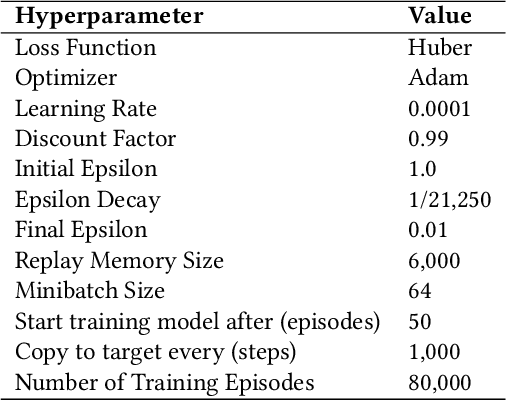
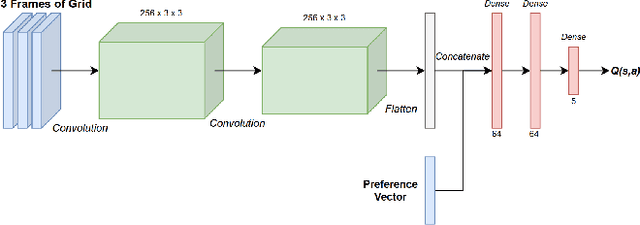

When developing reinforcement learning agents, the standard approach is to train an agent to converge to a fixed policy that is as close to optimal as possible for a single fixed reward function. If different agent behaviour is required in the future, an agent trained in this way must normally be either fully or partially retrained, wasting valuable time and resources. In this study, we leverage multi-objective reinforcement learning to create tunable agents, i.e. agents that can adopt a range of different behaviours according to the designer's preferences, without the need for retraining. We apply this technique to sequential social dilemmas, settings where there is inherent tension between individual and collective rationality. Learning a single fixed policy in such settings leaves one at a significant disadvantage if the opponents' strategies change after learning is complete. In our work, we demonstrate empirically that the tunable agents framework allows easy adaption between cooperative and competitive behaviours in sequential social dilemmas without the need for retraining, allowing a single trained agent model to be adjusted to cater for a wide range of behaviours and opponent strategies.