Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring TD error as a heuristic for $σ$ selection in Q
Paper and Code

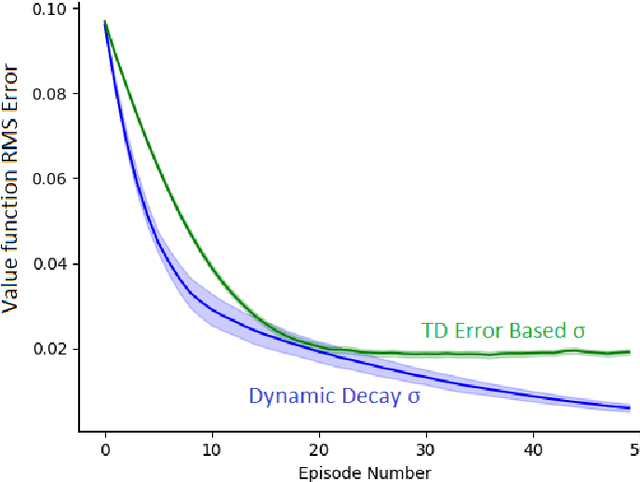
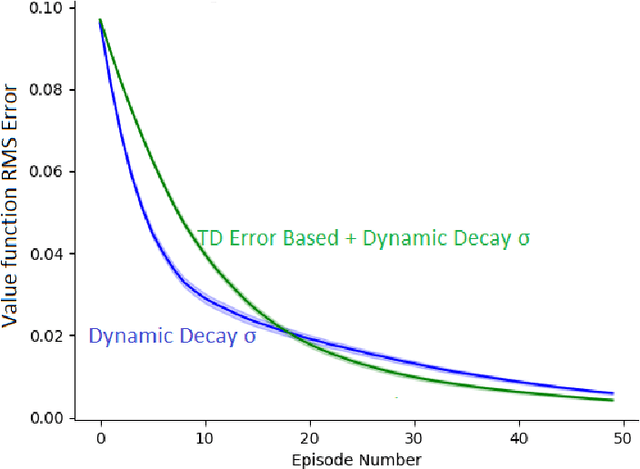

In the landscape of TD algorithms, the Q($\sigma$, $\lambda$) algorithm is an algorithm with the ability to perform a multistep backup in an online manner while also successfully unifying the concepts of sampling with using the expectation across all actions for a state. $\sigma \in [0, 1]$ indicates the extent to which sampling is used. Selecting the value of {\sigma} can be based on characteristics of the current state rather than having a constant value or being time based. This report explores the viability of such a TD-error based scheme.
View paper on