 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Explicit and Implicit Visual Relationships for Image Captioning
Paper and Code
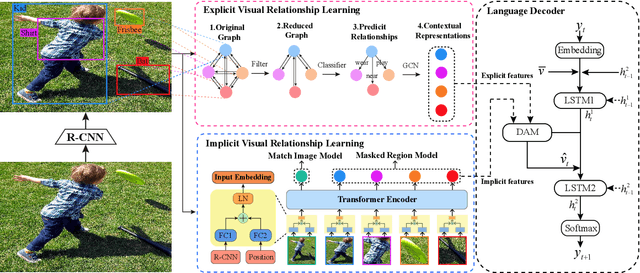
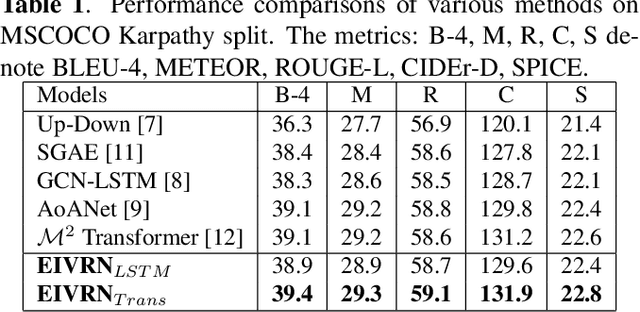

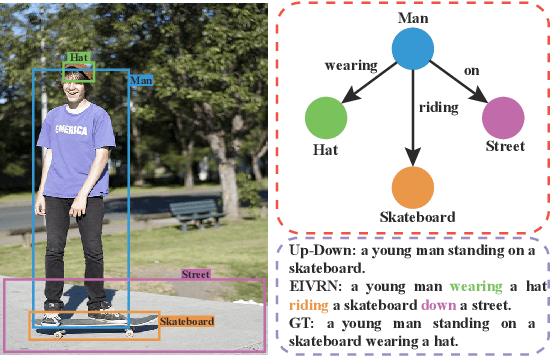
Image captioning is one of the most challenging tasks in AI, which aims to automatically generate textual sentences for an image. Recent methods for image captioning follow encoder-decoder framework that transforms the sequence of salient regions in an image into natural language descriptions. However, these models usually lack the comprehensive understanding of the contextual interactions reflected on various visual relationships between objects. In this paper, we explore explicit and implicit visual relationships to enrich region-level representations for image captioning. Explicitly, we build semantic graph over object pairs and exploit gated graph convolutional networks (Gated GCN) to selectively aggregate local neighbors' information. Implicitly, we draw global interactions among the detected objects through region-based bidirectional encoder representations from transformers (Region BERT) without extra relational annotations. To evaluate the effectiveness and superiority of our proposed method, we conduct extensive experiments on Microsoft COCO benchmark and achieve remarkable improvements compared with strong baselines.