 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Data Redundancy in Real-world Image Classification through Data Selection
Paper and Code
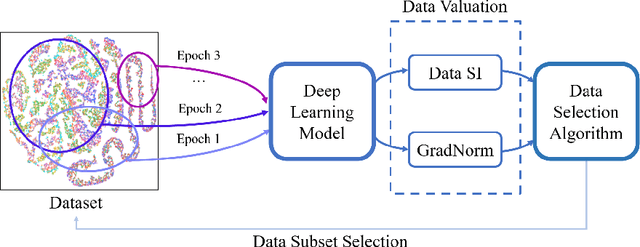
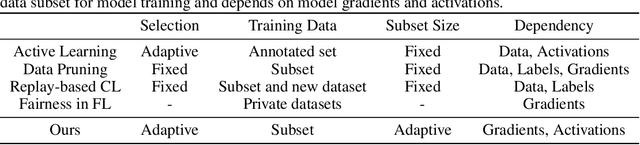
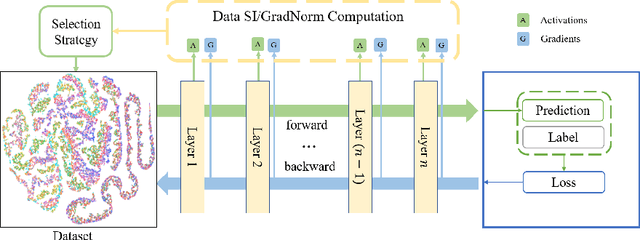

Deep learning models often require large amounts of data for training, leading to increased costs. It is particularly challenging in medical imaging, i.e., gathering distributed data for centralized training, and meanwhile, obtaining quality labels remains a tedious job. Many methods have been proposed to address this issue in various training paradigms, e.g., continual learning, active learning, and federated learning, which indeed demonstrate certain forms of the data valuation process. However, existing methods are either overly intuitive or limited to common clean/toy datasets in the experiments. In this work, we present two data valuation metrics based on Synaptic Intelligence and gradient norms, respectively, to study the redundancy in real-world image data. Novel online and offline data selection algorithms are then proposed via clustering and grouping based on the examined data values. Our online approach effectively evaluates data utilizing layerwise model parameter updates and gradients in each epoch and can accelerate model training with fewer epochs and a subset (e.g., 19%-59%) of data while maintaining equivalent levels of accuracy in a variety of datasets. It also extends to the offline coreset construction, producing subsets of only 18%-30% of the original. The codes for the proposed adaptive data selection and coreset computation are available (https://github.com/ZhenyuTANG2023/data_selection).