 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability for fair machine learning
Paper and Code
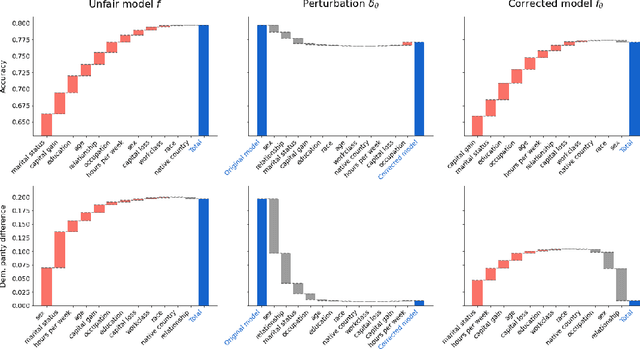
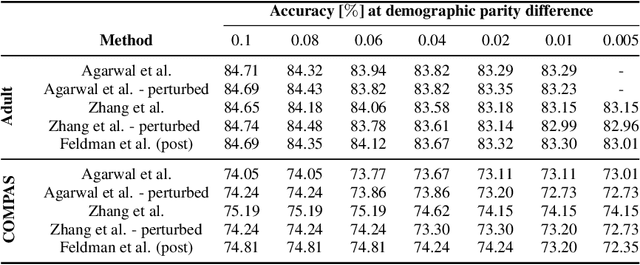
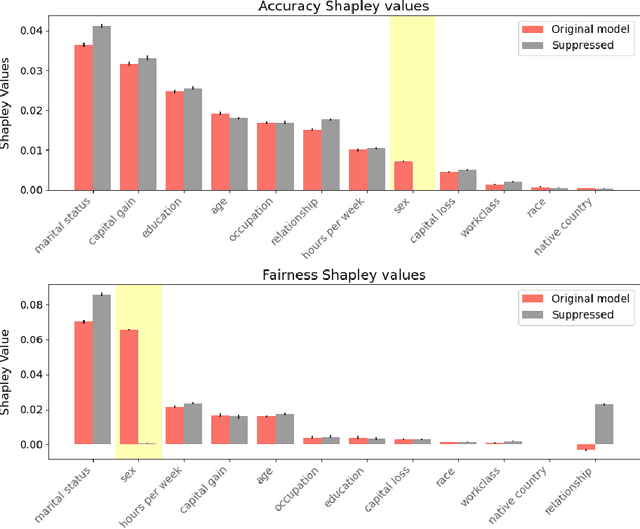
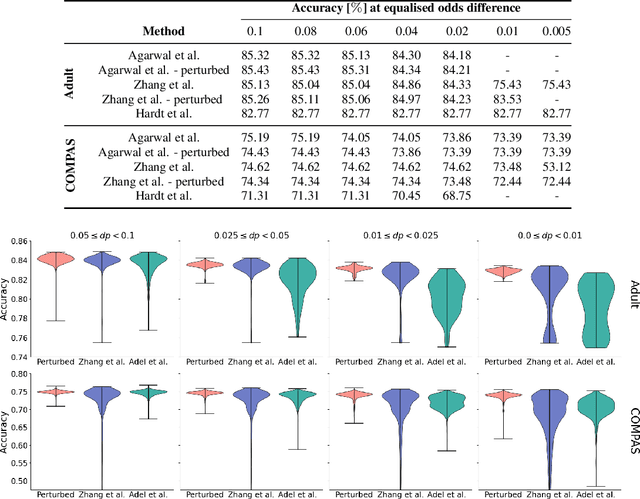
As the decisions made or influenced by machine learning models increasingly impact our lives, it is crucial to detect, understand, and mitigate unfairness. But even simply determining what "unfairness" should mean in a given context is non-trivial: there are many competing definitions, and choosing between them often requires a deep understanding of the underlying task. It is thus tempting to use model explainability to gain insights into model fairness, however existing explainability tools do not reliably indicate whether a model is indeed fair. In this work we present a new approach to explaining fairness in machine learning, based on the Shapley value paradigm. Our fairness explanations attribute a model's overall unfairness to individual input features, even in cases where the model does not operate on sensitive attributes directly. Moreover, motivated by the linearity of Shapley explainability, we propose a meta algorithm for applying existing training-time fairness interventions, wherein one trains a perturbation to the original model, rather than a new model entirely. By explaining the original model, the perturbation, and the fair-corrected model, we gain insight into the accuracy-fairness trade-off that is being made by the intervention. We further show that this meta algorithm enjoys both flexibility and stability benefits with no loss in performance.