Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExIt-OOS: Towards Learning from Planning in Imperfect Information Games
Paper and Code
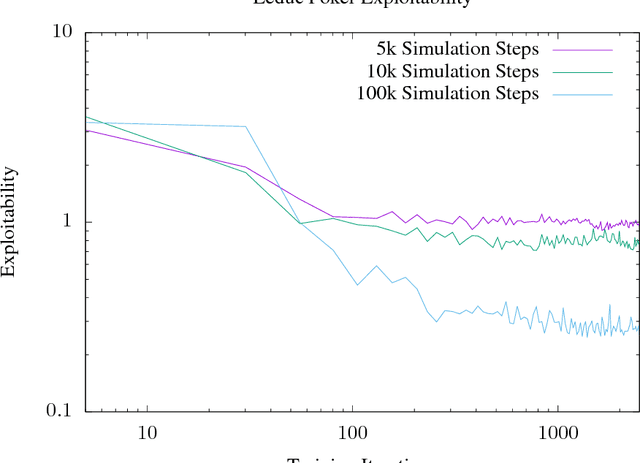
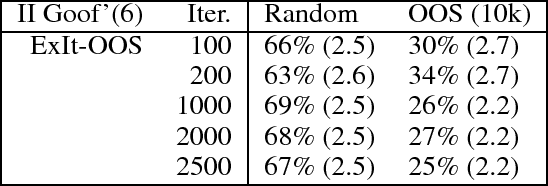

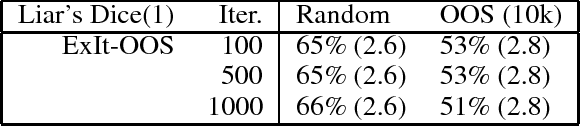
The current state of the art in playing many important perfect information games, including Chess and Go, combines planning and deep reinforcement learning with self-play. We extend this approach to imperfect information games and present ExIt-OOS, a novel approach to playing imperfect information games within the Expert Iteration framework and inspired by AlphaZero. We use Online Outcome Sampling, an online search algorithm for imperfect information games in place of MCTS. While training online, our neural strategy is used to improve the accuracy of playouts in OOS, allowing a learning and planning feedback loop for imperfect information games.
* 8 pages. 1 figure, 5 tables
View paper on