 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExample-Based Explanations of Random Forest Predictions
Paper and Code
Nov 24, 2023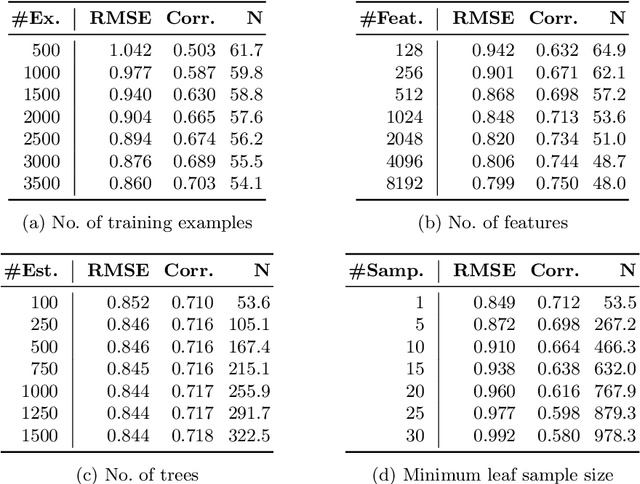



A random forest prediction can be computed by the scalar product of the labels of the training examples and a set of weights that are determined by the leafs of the forest into which the test object falls; each prediction can hence be explained exactly by the set of training examples for which the weights are non-zero. The number of examples used in such explanations is shown to vary with the dimensionality of the training set and hyperparameters of the random forest algorithm. This means that the number of examples involved in each prediction can to some extent be controlled by varying these parameters. However, for settings that lead to a required predictive performance, the number of examples involved in each prediction may be unreasonably large, preventing the user to grasp the explanations. In order to provide more useful explanations, a modified prediction procedure is proposed, which includes only the top-weighted examples. An investigation on regression and classification tasks shows that the number of examples used in each explanation can be substantially reduced while maintaining, or even improving, predictive performance compared to the standard prediction procedure.