Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Predictive Performance of Positive-Unlabelled Classifiers: a brief critical review and practical recommendations for improvement
Paper and Code
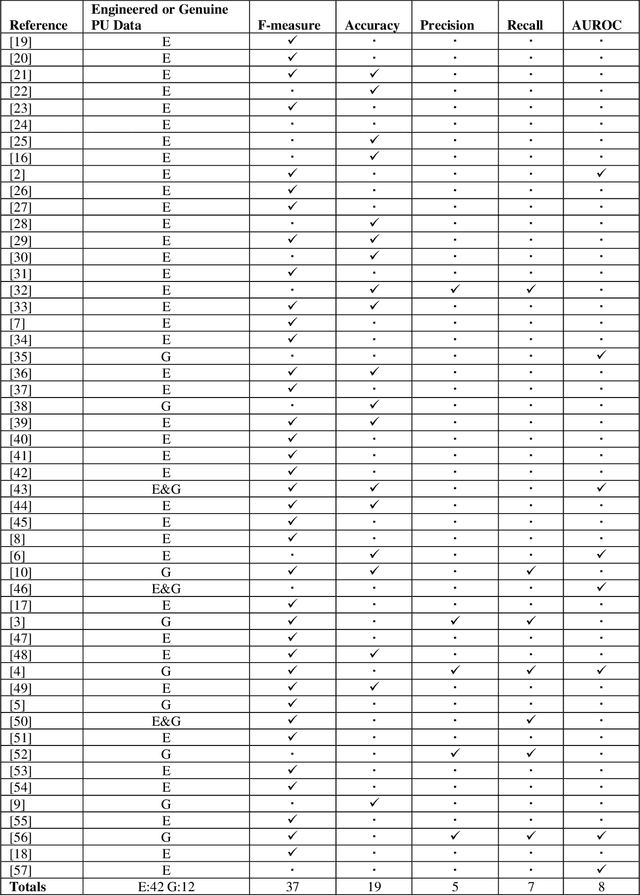
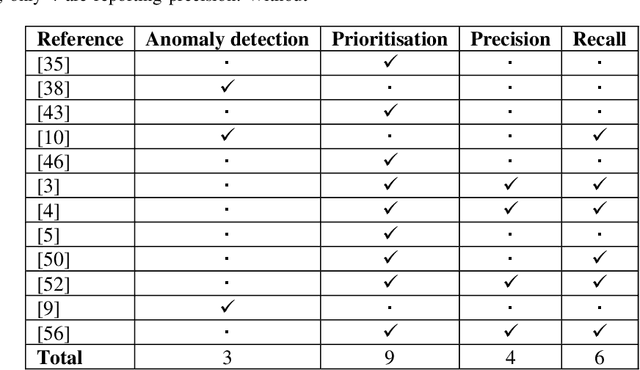
Positive-Unlabelled (PU) learning is a growing area of machine learning that aims to learn classifiers from data consisting of labelled positive and unlabelled instances. Whilst much work has been done proposing methods for PU learning, little has been written on the subject of evaluating these methods. Many popular standard classification metrics cannot be precisely calculated due to the absence of fully labelled data, so alternative approaches must be taken. This short commentary paper critically reviews the main PU learning evaluation approaches and the choice of predictive accuracy measures in 51 articles proposing PU classifiers and provides practical recommendations for improvements in this area.
View paper on