 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the performance of personal, social, health-related, biomarker and genetic data for predicting an individuals future health using machine learning: A longitudinal analysis
Paper and Code
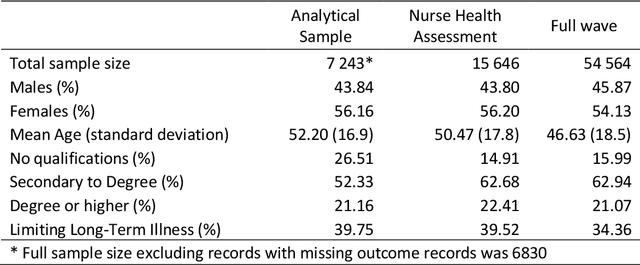
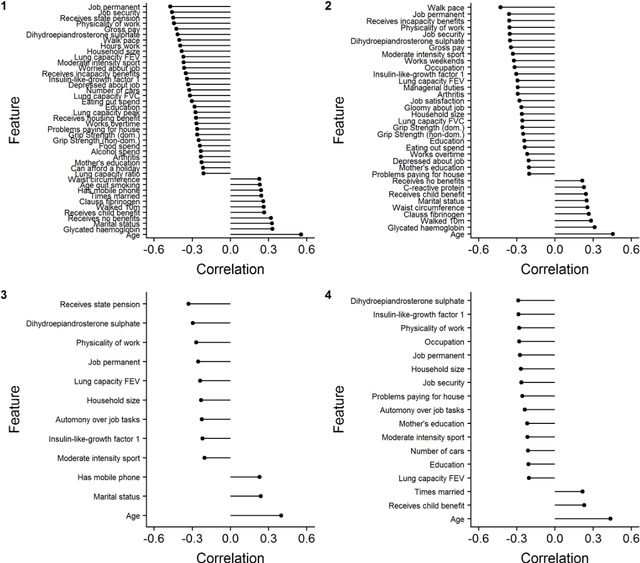
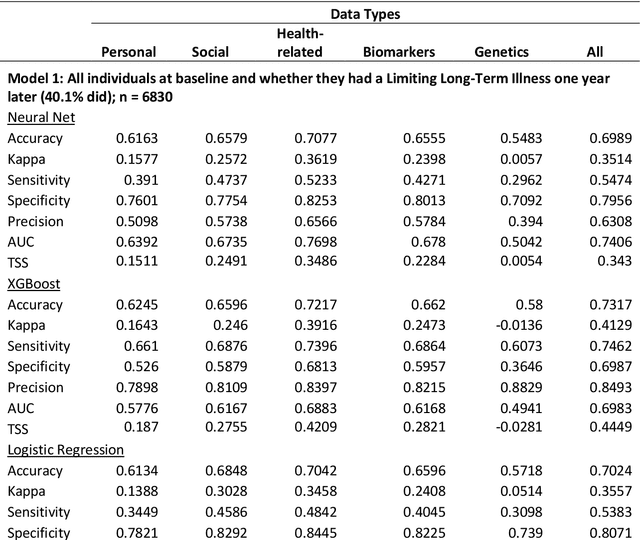
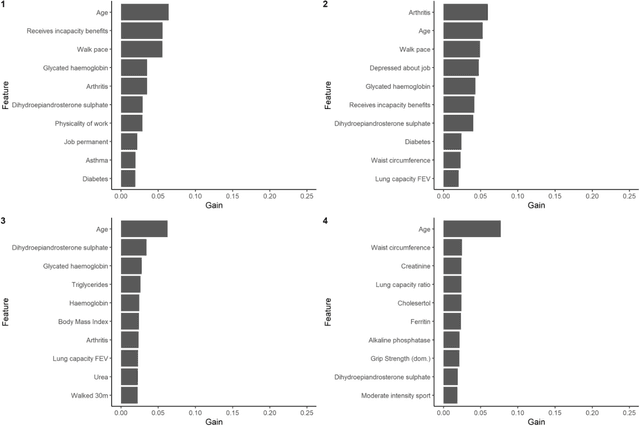
As we gain access to a greater depth and range of health-related information about individuals, three questions arise: (1) Can we build better models to predict individual-level risk of ill health? (2) How much data do we need to effectively predict ill health? (3) Are new methods required to process the added complexity that new forms of data bring? The aim of the study is to apply a machine learning approach to identify the relative contribution of personal, social, health-related, biomarker and genetic data as predictors of future health in individuals. Using longitudinal data from 6830 individuals in the UK from Understanding Society (2010-12 to 2015-17), the study compares the predictive performance of five types of measures: personal (e.g. age, sex), social (e.g. occupation, education), health-related (e.g. body weight, grip strength), biomarker (e.g. cholesterol, hormones) and genetic single nucleotide polymorphisms (SNPs). The predicted outcome variable was limiting long-term illness one and five years from baseline. Two machine learning approaches were used to build predictive models: deep learning via neural networks and XGBoost (gradient boosting decision trees). Model fit was compared to traditional logistic regression models. Results found that health-related measures had the strongest prediction of future health status, with genetic data performing poorly. Machine learning models only offered marginal improvements in model accuracy when compared to logistic regression models, but also performed well on other metrics e.g. neural networks were best on AUC and XGBoost on precision. The study suggests that increasing complexity of data and methods does not necessarily translate to improved understanding of the determinants of health or performance of predictive models of ill health.