Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Attribution Methods using White-Box LSTMs
Paper and Code
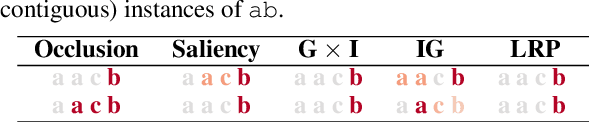

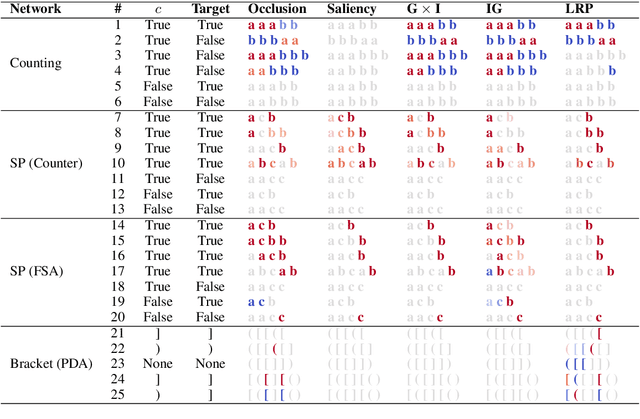
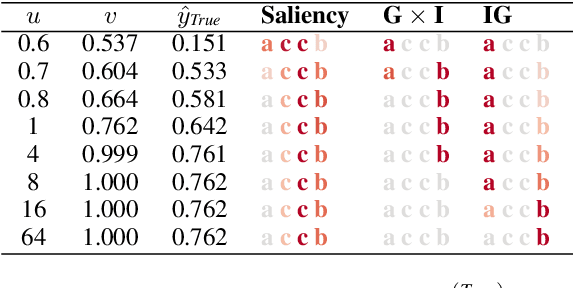
Interpretability methods for neural networks are difficult to evaluate because we do not understand the black-box models typically used to test them. This paper proposes a framework in which interpretability methods are evaluated using manually constructed networks, which we call white-box networks, whose behavior is understood a priori. We evaluate five methods for producing attribution heatmaps by applying them to white-box LSTM classifiers for tasks based on formal languages. Although our white-box classifiers solve their tasks perfectly and transparently, we find that all five attribution methods fail to produce the expected model explanations.
* To appear in the Proceedings of the 2020 EMNLP Workshop BlackboxNLP:
Analyzing and Interpreting Neural Networks for NLP
View paper on