 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Speech Recognition with High-Frame-Rate Features Extraction
Paper and Code
Jul 12, 2019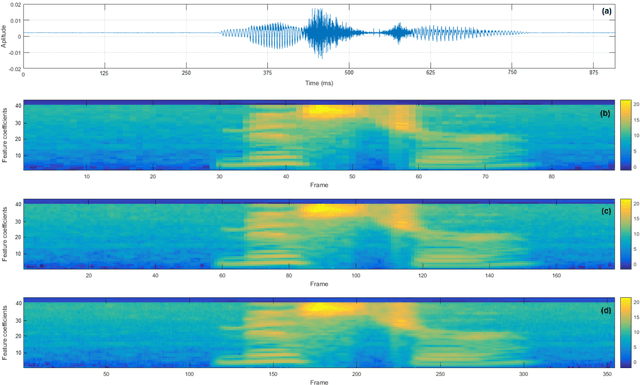
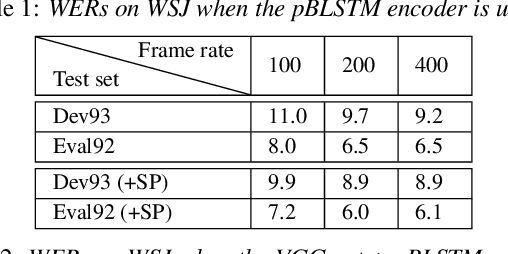
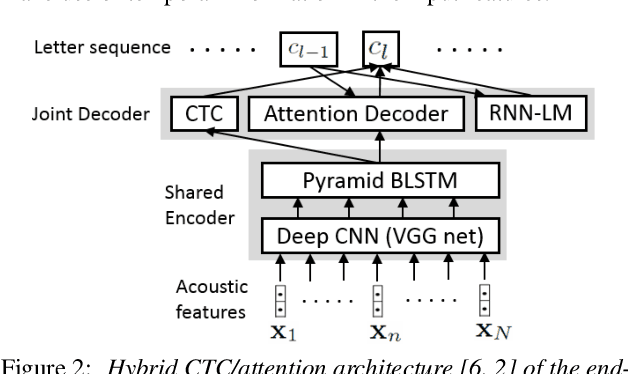
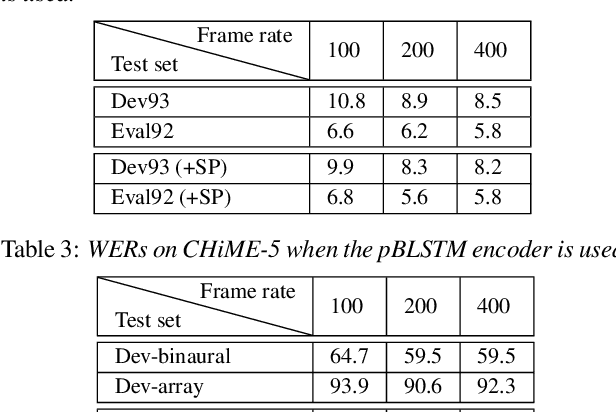
State-of-the-art end-to-end automatic speech recognition (ASR) extracts acoustic features from input speech signal every 10 ms which corresponds to a frame rate of 100 frames/second. In this report, we investigate the use of high-frame-rate features extraction in end-to-end ASR. High frame rates of 200 and 400 frames/second are used in the features extraction and provide additional information for end-to-end ASR. The effectiveness of high-frame-rate features extraction is evaluated independently and in combination with speed perturbation based data augmentation. Experiments performed on two speech corpora, Wall Street Journal (WSJ) and CHiME-5, show that using high-frame-rate features extraction yields improved performance for end-to-end ASR, both independently and in combination with speed perturbation. On WSJ corpus, the relative reduction of word error rate (WER) yielded by high-frame-rate features extraction independently and in combination with speed perturbation are up to 21.3% and 24.1%, respectively. On CHiME-5 corpus, the corresponding relative WER reductions are up to 2.8% and 7.9%, respectively, on the test data recorded by microphone arrays and up to 11.8% and 21.2%, respectively, on the test data recorded by binaural microphones.