 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end speech recognition modeling from de-identified data
Paper and Code
Jul 12, 2022
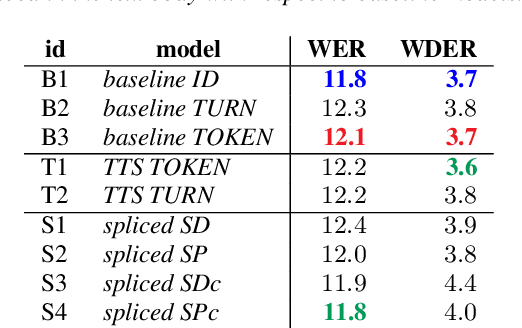


De-identification of data used for automatic speech recognition modeling is a critical component in protecting privacy, especially in the medical domain. However, simply removing all personally identifiable information (PII) from end-to-end model training data leads to a significant performance degradation in particular for the recognition of names, dates, locations, and words from similar categories. We propose and evaluate a two-step method for partially recovering this loss. First, PII is identified, and each occurrence is replaced with a random word sequence of the same category. Then, corresponding audio is produced via text-to-speech or by splicing together matching audio fragments extracted from the corpus. These artificial audio/label pairs, together with speaker turns from the original data without PII, are used to train models. We evaluate the performance of this method on in-house data of medical conversations and observe a recovery of almost the entire performance degradation in the general word error rate while still maintaining a strong diarization performance. Our main focus is the improvement of recall and precision in the recognition of PII-related words. Depending on the PII category, between $50\% - 90\%$ of the performance degradation can be recovered using our proposed method.